- เผยแพร่เมื่อ
อัลกอริทึมการเรียนรู้ของเครื่อง ที่นักวิทยาศาสตร์ข้อมูลควรทราบ
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
ไม่ใช่สำหรับทุกคน
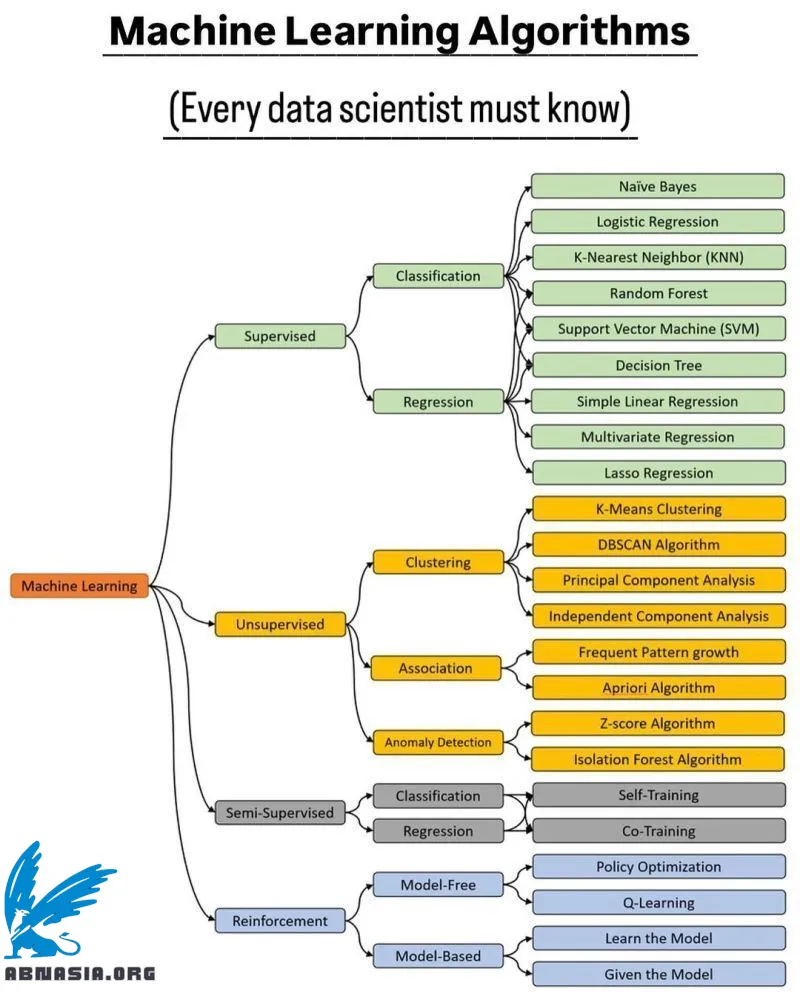
เครื่องมือการเรียนรู้ (Machine Learning) เป็นพลังงานที่ขับเคลื่อนสิ่งต่างๆ มากมายรอบตัวเรา ตั้งแต่ระบบแนะนำผลิตภัณฑ์ไปจนถึงรถยนต์ไร้คนขับ
อย่างไรก็ตาม การทำความเข้าใจประเภทต่างๆ ของอัลกอริทึมอาจเป็นเรื่องที่ยาก
คู่มือนี้เป็นคู่มือเร็วและง่ายสำหรับประเภทหลัก 4 ประเภท ได้แก่ การเรียนรู้แบบมีผู้ดูแล การเรียนรู้แบบไม่มีผู้ดูแล การเรียนรู้แบบกึ่งมีผู้ดูแล และการเรียนรู้แบบเสริมแรง
- การเรียนรู้แบบมีผู้ดูแล
ในการเรียนรู้แบบมีผู้ดูแล โมเดลจะเรียนรู้จากตัวอย่างที่มีคำตอบแล้ว (ข้อมูลที่มีฉลาก) เป้าหมายคือให้โมเดลคาดการณ์ผลลัพธ์ที่ถูกต้องเมื่อมีข้อมูลใหม่
อัลกอริทึมการเรียนรู้แบบมีผู้ดูแลทั่วไป ได้แก่
➡️ การถดถอยเชิงเส้น (Linear Regression) - สำหรับการคาดการณ์ค่าเชิงต่อเนื่อง เช่น ราคาเรือน
➡️ การถดถอยเชิงลอจิสติก (Logistic Regression) - สำหรับการคาดการณ์หมวดหมู่ เช่น สแปมหรือไม่ใช่สแปม
➡️ ต้นการตัดสินใจ (Decision Trees) - สำหรับการตัดสินใจแบบขั้นตอน
➡️ ระบบเพื่อนบ้านที่ใกล้ที่สุด (K-Nearest Neighbors) - สำหรับการค้นหาจุดข้อมูลที่คล้ายกัน
➡️ ป่าแบบสุ่ม (Random Forests) - ชุดของต้นการตัดสินใจเพื่อความแม่นยำที่ดีกว่า
➡️ โครงข่ายประสาทเทียม (Neural Networks) - พื้นฐานของการเรียนรู้เชิงลึกที่เลียนแบบสมองมนุษย์
- การเรียนรู้แบบไม่มีผู้ดูแล
ในการเรียนรู้แบบไม่มีผู้ดูแล โมเดลจะสำรวจรูปแบบในข้อมูลที่ไม่มีฉลาก มันค้นหาความสัมพันธ์หรือกลุ่มที่ซ่อนอยู่
อัลกอริทึมการเรียนรู้แบบไม่มีผู้ดูแลที่ได้รับความนิยม ได้แก่
➡️ การแบ่งกลุ่มแบบ K-Means (K-Means Clustering) - สำหรับการแบ่งกลุ่มข้อมูล
➡️ การแบ่งกลุ่มแบบเชิงลำดับ (Hierarchical Clustering) - สำหรับการสร้างต้นของกลุ่ม
➡️ การวิเคราะห์องค์ประกอบหลัก (Principal Component Analysis) - สำหรับการลดข้อมูลให้เหลือส่วนที่สำคัญที่สุด
➡️ อัตลักษณ์แบบอัตโนมัติ (Autoencoders) - สำหรับการค้นหาการแทนข้อมูลที่ง่ายขึ้น
- การเรียนรู้แบบกึ่งมีผู้ดูแล
สิ่งนี้เป็นการผสมผสานระหว่างการเรียนรู้แบบมีผู้ดูแลและการเรียนรู้แบบไม่มีผู้ดูแล มันใช้ข้อมูลที่มีฉลากจำนวนเล็กน้อยพร้อมกับข้อมูลที่ไม่มีฉลากจำนวนมากเพื่อปรับปรุงการเรียนรู้
อัลกอริทึมการเรียนรู้แบบกึ่งมีผู้ดูแลทั่วไป ได้แก่
➡️ การแพร่กระจายฉลาก (Label Propagation) - สำหรับการแพร่กระจายฉลากผ่านจุดข้อมูลที่เชื่อมต่อ
➡️ การแบ่งประเภทแบบกึ่งมีผู้ดูแล (Semi-Supervised SVM) - สำหรับการผสมข้อมูลที่มีฉลากและไม่มีฉลาก
➡️ วิธีการแบบกราฟ (Graph-Based Methods) - สำหรับการใช้โครงสร้างกราฟเพื่อปรับปรุงการเรียนรู้
- การเรียนรู้แบบเสริมแรง
ในการเรียนรู้แบบเสริมแรง โมเดลจะเรียนรู้โดยการลองผิดลองถูก มันโต้ตอบกับสภาพแวดล้อม รับคำติชม (รางวัลหรือการลงโทษ) และเรียนรู้วิธีการกระทำเพื่อเพิ่มรางวัลให้สูงสุด
อัลกอริทึมการเรียนรู้แบบเสริมแรงที่ได้รับความนิยม ได้แก่
➡️ การเรียนรู้แบบ Q-Learning (Q-Learning) - สำหรับการเรียนรู้การกระทำที่ดีที่สุดตามเวลา
➡️ โครงข่ายประสาทเทียมแบบลึก Q (Deep Q-Networks) - การผสมผสาน Q-Learning กับการเรียนรู้เชิงลึก
➡️ วิธีการแบบนโยบายการเรียนรู้ (Policy Gradient Methods) - สำหรับการเรียนรู้นโยบายโดยตรง
➡️ การเพิ่มประสิทธิภาพแบบ Proximal Policy (Proximal Policy Optimization) - สำหรับการเรียนรู้ที่มีเสถียรภาพและมีประสิทธิภาพ
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA