- เผยแพร่เมื่อ
เพิ่มความเร็วการอนุมาน LLM ด้วยการถอดรหัสแบบคาดเดา
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
จำ MSN Messenger ได้ไหม
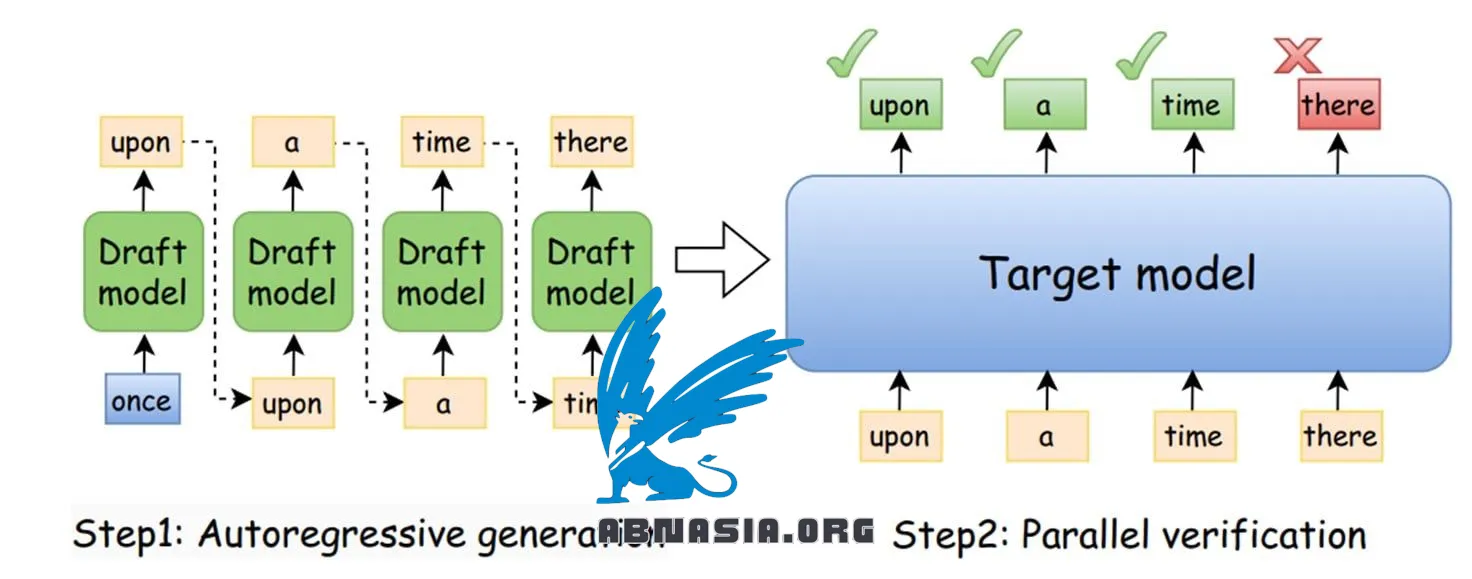
อะไรคือ Speculative Decoding?
เป็นเทคนิคที่ใช้โมเดลฉบับร่าง (SLM) เพื่อทำงานร่วมกับโมเดลหลัก LLM:
1️⃣ โมเดลฉบับร่างทำนายโทเค็นถัดไป K ตัว
2️⃣ โมเดลหลัก LLM ตรวจสอบและแก้ไขตามความจำเป็น
3️⃣ หากมีความไม่ตรงกัน โมเดลหลัก LLM จะดำเนินลำดับต่อ และโมเดลฉบับร่างจะเริ่มต้นใหม่ด้วยข้อมูลอินพุตที่อัปเดต
เหตุผลที่มันทำงานได้:
• เร็วขึ้นถึง 3 เท่าสำหรับการเติมโค้ด
• เร็วขึ้นถึง 2 เท่าสำหรับการสรุปข้อความ การสร้างข้อความ และคำแนะนำ
โมเดลฉบับร่างพรีเทรน:
• Llama-3.1-8B-FastDraft-150M
• Phi-3-mini-FastDraft-50M
เหตุผลที่มันสำคัญ:
มันทำให้ LLM เร็วขึ้น มีประสิทธิภาพมากขึ้น และพร้อมสำหรับงานในโลกแห่งความเป็นจริง
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA