- เผยแพร่เมื่อ
เราต้องฝึกโมเดลเพื่อเข้าใจว่ามันจะดีแค่ไหนหรือไม่
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
แนวคิดนั้นง่ายดาย คือ การแปลงข้อมูลเมต้าดาต้าให้เป็นคุณลักษณะ ฝึกโมเดลเพื่อคาดการณ์มาตรการประสิทธิภาพโดยใช้คุณลักษณะเหล่านั้น และใช้โมเดลเมต้าดาต้าเพื่อค้นหาพื้นที่การปรับแต่งเมื่อปรับแต่งโมเดลอื่น
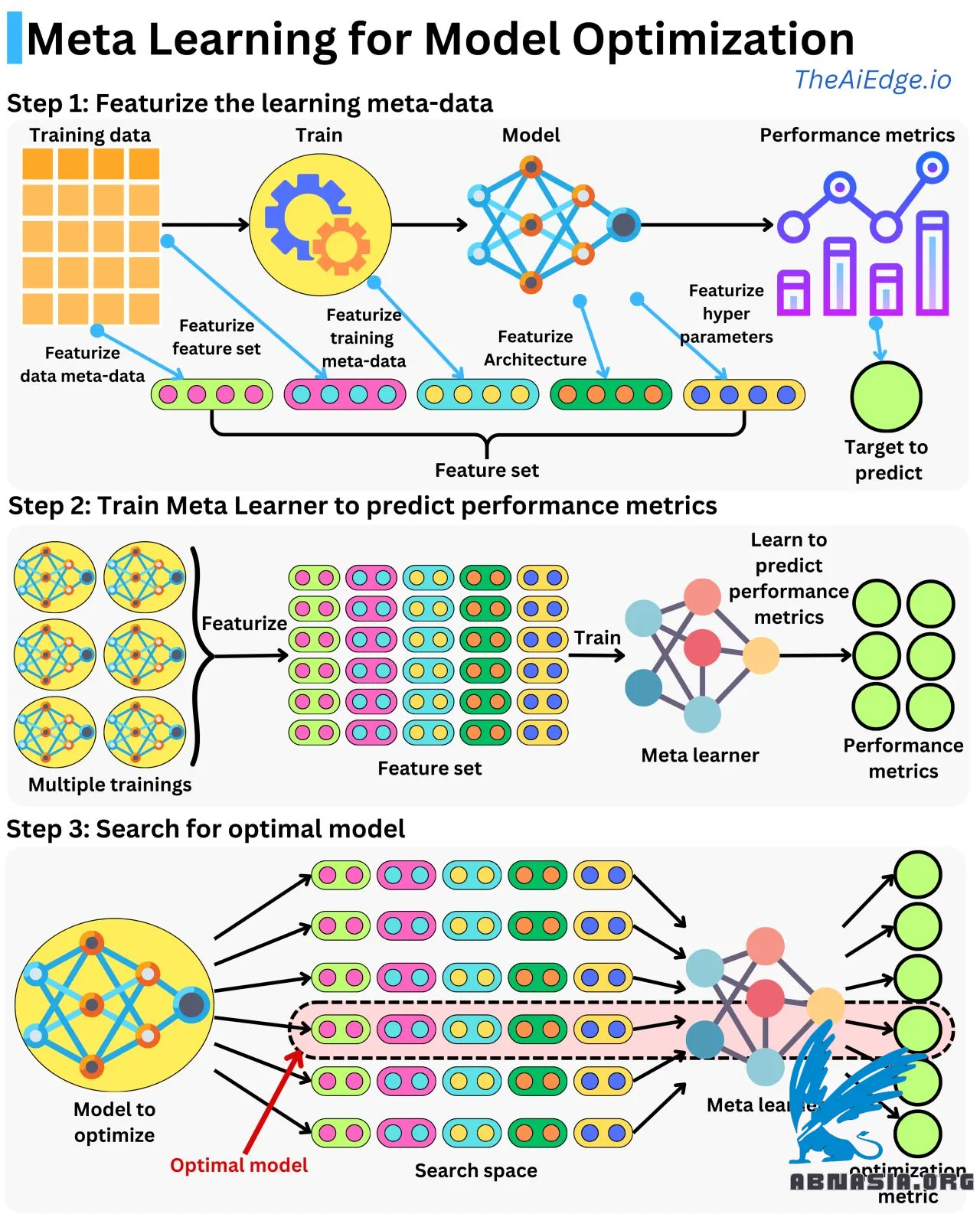
เราต้องฝึกโมเดลเพื่อให้เข้าใจว่ามันจะดีแค่ไหนหรือไม่? เราไม่สามารถ "เดา" ศักยภาพในการทำนายของโมเดลได้แค่จากโครงสร้างหรือพารามิเตอร์การฝึกเท่านั้นหรือ? นั่นคือความคิดเบื้องหลังของ Meta-Learning: เรียนรู้รูปแบบที่ทำให้โมเดลหนึ่งดีกว่าอีกโมเดลหนึ่งสำหรับงานเรียนรู้บางอย่าง!
แนวคิดนั้นง่ายมาก: สร้างคุณลักษณะจากข้อมูลเมตาของการเรียนรู้ ฝึกโมเดลเพื่อคาดการณ์มาตรวัดประสิทธิภาพด้วยคุณลักษณะเหล่านั้น และใช้โมเดลเมตานั้นเพื่อค้นหาพื้นที่การปรับให้เหมาะสมเมื่อปรับโมเดลอื่น
การสร้างคุณลักษณะจากข้อมูลเมตาของการเรียนรู้หมายความว่าเราสร้างคุณลักษณะจากการตั้งค่าการฝึก เราสามารถจับโครงสร้างของเครือข่ายเป็นเวกเตอร์คุณลักษณะแบบ one-hot encoded เราสามารถจับค่าพารามิเตอร์ไฮเปอร์และพารามิเตอร์การฝึก เช่น จำนวนรอบการฝึกหรือฮาร์ดแวร์ (CPU / GPU) เราสามารถขยายพื้นที่คุณลักษณะเมตาของเราไปยังชุดข้อมูลที่ใช้ในการฝึก เช่น เราสามารถรวมการแสดงคุณลักษณะแบบ one-hot encoded และจำนวนแบบทดสอบที่ใช้ (สิ่งนี้จะทำให้คุณสามารถทำการเลือกคุณลักษณะได้เช่นกัน) เราสามารถจับอะไรที่อาจมีอิทธิพลต่อการเรียนรู้และมาตรวัดประสิทธิภาพที่ได้ผลลัพธ์ คุณลักษณะเมตาที่คุณรวมมากเท่าไหร่ พื้นที่ที่คุณจะสามารถปรับให้เหมาะสมมากขึ้น แต่ก็ยากที่จะเรียนรู้ตัวแปรเป้าหมายได้อย่างถูกต้อง
ตอนนี้คุณสามารถสร้างคุณลักษณะจากการทดลองฝึกได้ คุณสามารถฝึกโมเดลเมตาเพื่อเรียนรู้ความสัมพันธ์ระหว่างพารามิเตอร์การฝึกและมาตรวัดประสิทธิภาพ เนื่องจากคุณมีเพียงไม่กี่ตัวอย่าง โมเดลเมตาของคุณจึงควรเป็นโมเดลที่เรียบง่าย เช่น การถดถอยเชิงเส้นหรือเครือข่ายประสาทเทียมตื้น
ตอนนี้คุณมีโมเดลที่เข้าใจความสัมพันธ์ระหว่างข้อมูลเมตาของการเรียนรู้และมาตรวัดประสิทธิภาพ คุณสามารถค้นหาข้อมูลเมตาของการเรียนรู้ที่เพิ่มประสิทธิภาพมาตรวัดได้มากที่สุด เนื่องจากคุณมีโมเดล คุณสามารถประเมินข้อมูลเมตาของการเรียนรู้ที่แตกต่างกันไปเป็นพันล้านรายการในเวลาเพียงไม่กี่วินาทีและเข้าใกล้คุณลักษณะเมตาที่เหมาะสมที่สุดได้อย่างรวดเร็ว วิธีการทั่วไปคือการใช้การเรียนรู้เสริม (Reinforcement Learning) หรือการปรับให้เหมาะสมแบบกำกับ (Supervised Fine-tuning) การปรับให้เหมาะสมแบบกำกับหมายความว่าถ้าคุณมีข้อมูลฝึกเฉพาะหรือถ้าคุณต้องการเน้นไปที่พื้นที่การค้นหาส่วนใดส่วนหนึ่ง คุณสามารถฝึกโมเดลใหม่สองสามตัวบนข้อมูลนั้นและได้มาตรวัดประสิทธิภาพที่ได้ผลลัพธ์ สิ่งนี้จะทำให้คุณปรับโมเดลเมตาของคุณให้เหมาะสมเพื่อให้ได้การค้นหาที่ดีขึ้น
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA