- เผยแพร่เมื่อ
การจัดอันดับแชทบอท: งานที่แตกต่างกัน ผู้ชนะที่แตกต่างกัน
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
ไม่ค่อยเป็นที่รู้จักว่า Chatbot Arena ตีพิมพ์เรตติ้งตามหมวดหมู่สำหรับพรอมต์ เช่น คณิตศาสตร์ การเขียนโค้ด หรือ การเขียนเชิงสร้างสรรค์ รวมถึงการปรับเปลี่ยนรูปแบบ
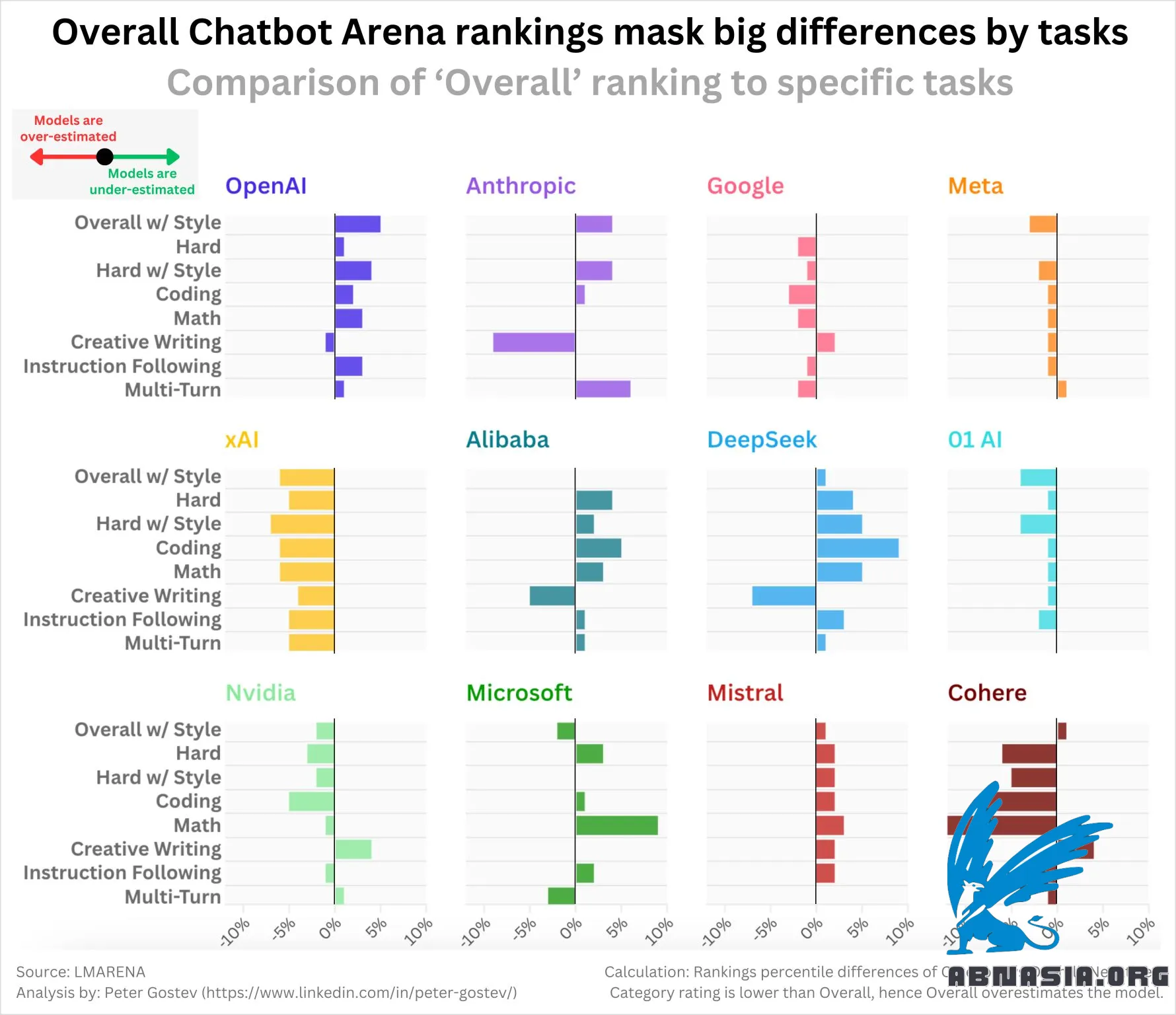
หมายความว่าเราสามารถมองเห็น 'ประสิทธิภาพหลัก' ของโมเดลสำหรับงานเฉพาะได้
ฉันสนใจที่จะสำรวจว่าห้องปฏิบัติการบางแห่งมีแนวโน้มที่จะถูกประเมินต่ำหรือสูงเกินไปโดย 'คะแนนโดยรวม' สำหรับงานต่างๆ ผลลัพธ์จริงๆ แล้วไม่ได้เป็นไปตามที่ฉันคาดหวัง:
โมเดลของ OpenAI ส่วนใหญ่ถูกประเมินต่ำเกินไป (หมายความว่าพวกมันแข็งแกร่งกว่าหากคุณดูคะแนนรายบุคคล)
xAI, Google, Meta, 01 (ห้องปฏิบัติการ ไม่ใช่โมเดล), Cohere, Nvidia ทั้งหมดถูกประเมินสูงเกินไป
DeepSeek, Mistral, Alibaba (โมเดล Qwen) ถูกประเมินต่ำเกินไป
Anthropic ผสมผสานกัน - การประเมินสูงเกินไปสำหรับการเขียนเชิงสร้างสรรค์เป็นเรื่องที่น่าสนใจ
คำแนะนำ หากคุณต้องการดูโมเดลที่ดีที่สุด ฉันจะแนะนำให้ดูที่ 'ยากด้วยการควบคุมสไตล์' - ซึ่ง Sonnet 3.6, o1-preview และ Google-Exp-1121 อยู่ในอันดับแรกเท่ากัน - สอดคล้องกับความคิดของฉันเกี่ยวกับโมเดลที่ดีที่สุดมากขึ้น
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA