- เผยแพร่เมื่อ
โมเดลใหม่ที่น่าประทับใจจากประเทศจีน: Kimi k1.5: การขยายการเรียนรู้แบบเสริมกำลังด้วย LLMs
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
🚀 นำเสนอ Kimi k1.5 --- โมเดลหลายรูปแบบระดับ o1
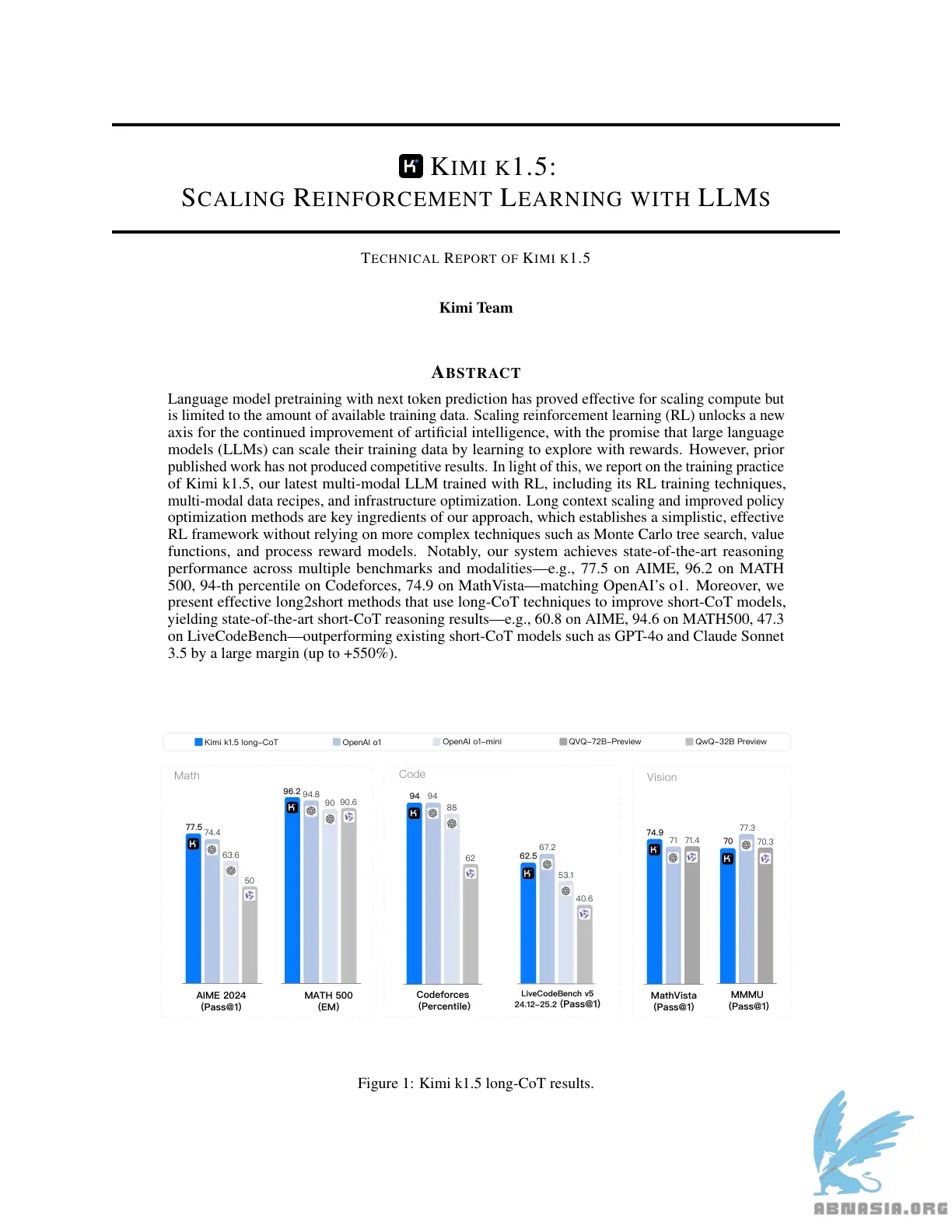

ผลการทำงานของ Sota short-CoT เหนือกว่า GPT-4o และ Claude Sonnet 3.5 ใน 📐AIME, 📐MATH-500, 💻 LiveCodeBench มากถึง +550%
ผลการทำงานของ Long-CoT เหมือนกับ o1 ในหลายรูปแบบ (👀MathVista, 📐AIME, 💻Codeforces, etc)
การฝึกฝนแบบเริ่มต้นของโมเดลภาษาโดยใช้การคาดเดาตัวถัดไปได้พิสูจน์แล้วว่ามีประสิทธิภาพในการปรับขนาดการคำนวณ แต่จำกัดอยู่ที่ปริมาณข้อมูลฝึกที่มีอยู่ การเพิ่มการเรียนรู้แบบเสริมกำลัง (RL) เปิดโอกาสใหม่สำหรับการปรับปรุงความฉลาดเทียมอย่างต่อเนื่อง โดยมีคำมั่นว่าโมเดลภาษาขนาดใหญ่ (LLMs) สามารถปรับขนาดข้อมูลฝึกได้โดยการเรียนรู้เพื่อสำรวจด้วยรางวัล อย่างไรก็ตาม ผลงานที่เผยแพร่ในอดีตไม่ได้ให้ผลลัพธ์ที่แข่งขันได้ ในแสงสว่างนี้ เรารายงานเกี่ยวกับแนวทางปฏิบัติในการฝึกของ Kimi k1.5 โมเดล LLM หลายรูปแบบที่ฝึกด้วย RL ของเรา รวมถึงเทคนิคการฝึก RL สูตรข้อมูลหลายรูปแบบ และการปรับโครงสร้างพื้นฐาน การปรับขนาดบริบทยาวและวิธีการเพิ่มประสิทธิภาพนโยบายที่ดีขึ้นเป็นส่วนผสมหลักของแนวทางของเรา ซึ่งสร้างเฟรมเวิร์ก RL ที่เรียบง่ายและมีประสิทธิภาพโดยไม่ต้องอาศัยเทคนิคที่ซับซ้อนกว่า เช่น การค้นหาต้นไม้แบบ Monte Carlo ฟังก์ชันค่า และโมเดลรางวัลกระบวนการ นอกจากนี้ ระบบของเรายังบรรลุผลการให้เหตุผลที่ดีที่สุดในหลายรูปแบบและหลายมาตรฐาน เช่น 77.5 ใน AIME, 96.2 ใน MATH 500, 94-th เปอร์เซ็นต์ในการ Codeforces, 74.9 ใน MathVista ซึ่งเทียบเท่ากับ o1 ของ OpenAI อีกทั้งเรายังนำเสนอวิธีการ long2short ที่มีประสิทธิภาพ ซึ่งใช้เทคนิคบริบทยาวเพื่อปรับปรุงโมเดลบริบทสั้น โดยให้ผลลัพธ์เหตุผลที่ดีที่สุดในบริบทสั้น เช่น 60.8 ใน AIME, 94.6 ใน MATH500, 47.3 ใน LiveCodeBench ซึ่งเหนือกว่าโมเดลบริบทสั้นที่มีอยู่ เช่น GPT-4o และ Claude Sonnet 3.5 มากถึง +550%
มีส่วนผสมหลักๆ ในการออกแบบและฝึกของ k1.5
การปรับขนาดบริบทยาว เราปรับขนาดหน้าต่างบริบทของ RL เป็น 128k และสังเกตเห็นการปรับปรุงประสิทธิภาพที่ต่อเนื่องเมื่อเพิ่มความยาวบริบท ความคิดหลักเบื้องหลังแนวทางของเราคือการใช้การวาดใหม่บางส่วนเพื่อปรับปรุงประสิทธิภาพการฝึก โดยตัวอย่างเช่น การตัวอย่างใหม่โดยใช้เศษส่วนใหญ่ของเส้นทางก่อนหน้า หลีกเลี่ยงค่าใช้จ่ายในการสร้างเส้นทางใหม่จากศูนย์ การสังเกตของเราชี้ให้เห็นว่าความยาวบริบทเป็นมิติหลักในการปรับขนาด RL ต่อไป
การเพิ่มประสิทธิภาพนโยบายที่ดีขึ้น เราได้รูปแบบการเรียนรู้แบบ RL โดยใช้เทคนิคบริบทยาวและใช้การปรับเปลี่ยนแบบ_mirror descent_ออนไลน์สำหรับการเพิ่มประสิทธิภาพนโยบายที่มั่นคง อัลกอริทึมนี้ได้รับการปรับปรุงเพิ่มเติมโดยกลยุทธ์การตัวอย่างที่มีประสิทธิภาพของเรา ค่าปรับโทษความยาว และการปรับโครงสร้างสูตรข้อมูล
เฟรมเวิร์กที่เรียบง่าย การปรับขนาดบริบทยาว เมื่อรวมกับวิธีการเพิ่มประสิทธิภาพนโยบายที่ดีขึ้น สร้างเฟรมเวิร์ก RL ที่เรียบง่ายสำหรับการเรียนรู้ด้วย LLMs เนื่องจากเราสามารถปรับขนาดความยาวบริบทได้ CoTs ที่เรียนรู้จึงแสดงคุณสมบัติของการวางแผน การสะท้อน และการแก้ไข การเพิ่มความยาวบริบทมีผลต่อการเพิ่มจำนวนขั้นตอนการค้นหา ดังนั้น เราจึงแสดงให้เห็นว่าสามารถบรรลุประสิทธิภาพที่แข็งแกร่งได้โดยไม่ต้องอาศัยเทคนิคที่ซับซ้อนกว่า เช่น การค้นหาต้นไม้แบบ Monte Carlo ฟังก์ชันค่า และโมเดลรางวัลกระบวนการ
หลายรูปแบบ โมเดลของเราฝึกด้วยข้อมูลข้อความและภาพ ซึ่งมีความสามารถในการให้เหตุผลร่วมกันในสองรูปแบบนี้
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องกรทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA