- เผยแพร่เมื่อ
โมเดลการเรียนรู้ของเครื่อง: วิธีการบีบอัดโมเดล
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
ทำไม เพราะตอนนี้มันใหญ่เกินไปแล้ว
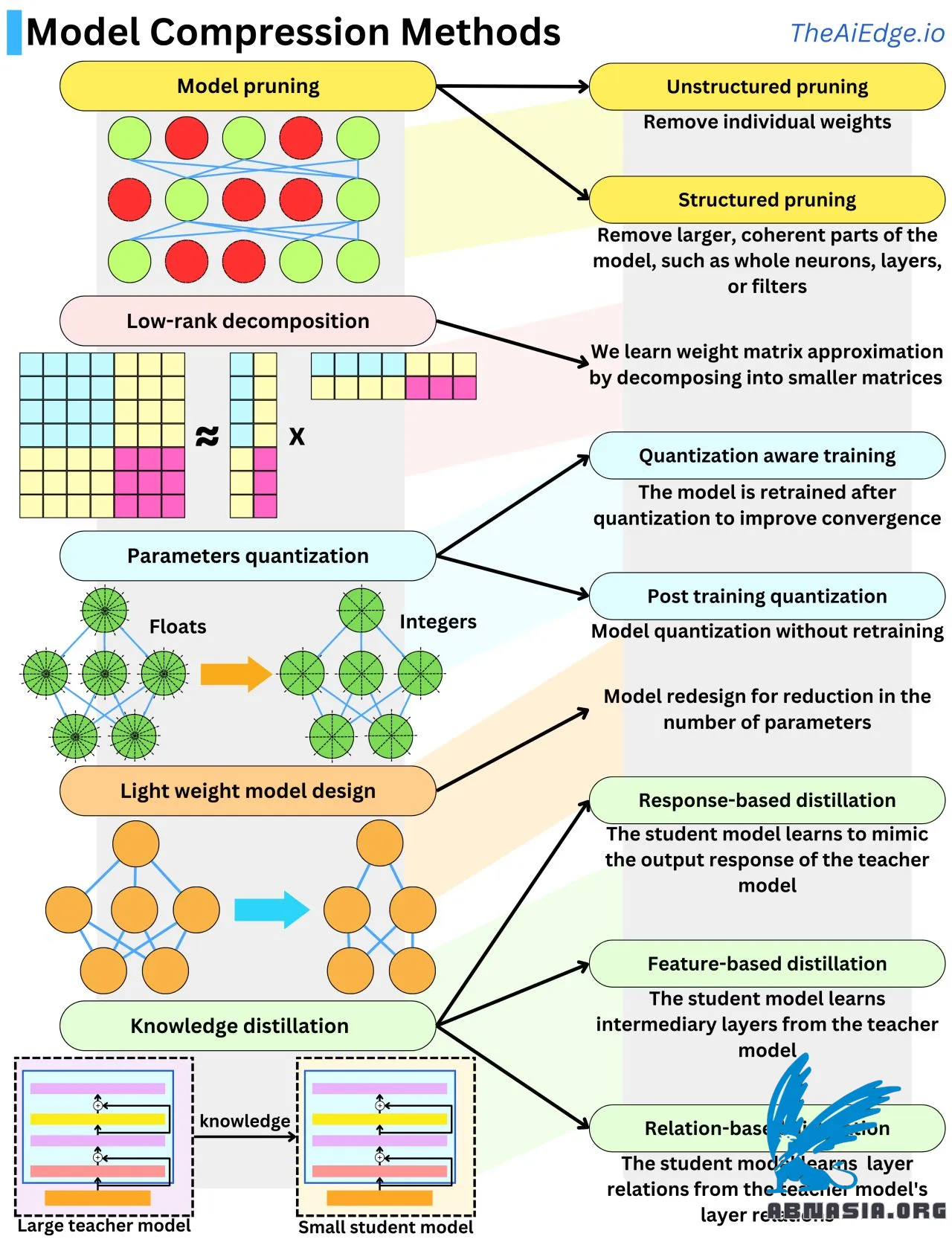
เมื่อไม่นานมานี้ โมเดล Machine Learning ที่ใหญ่ที่สุดซึ่งผู้คนส่วนใหญ่จะจัดการมีขนาดหน่วยความจำเพียงไม่กี่ GB เท่านั้น แต่ปัจจุบันโมเดลสร้างสรรค์ใหม่ทุกตัวที่ออกมามีจำนวนพารามิเตอร์ระหว่าง 1 พันล้านถึง 1 ล้านล้านพารามิเตอร์! หากต้องการเข้าใจขนาดของโมเดลเหล่านี้ ค่าพารามิเตอร์แบบลอยตัวหนึ่งค่าซึ่งเป็น 32 บิต หรือ 4 ไบต์ (หรือ 2 ไบต์สำหรับ Float16) ดังนั้นโมเดลใหม่เหล่านี้สามารถมีขนาดหน่วยความจำระหว่าง 4 GB ถึง 4 TB ในแต่ละครั้ง โดยใช้ฮาร์ดแวร์ที่มีราคาแพง และระหว่างการทำงานของอัลกอริทึมการถอยกลับ โมเดลเหล่านี้อาจต้องการหน่วยความจำมากถึง 10 เท่าของจำนวนพารามิเตอร์ เนื่องจากขนาดที่เพิ่มขึ้นอย่างมาก จึงมีการวิจัยมากมายเพื่อลดขนาดโมเดลโดยยังคงประสิทธิภาพไว้ มีเทคนิคหลัก 5 วิธีในการบีบอัดขนาดโมเดล
การตัดแต่งโมเดล (Model pruning) คือการลบความสำคัญของน้ำหนักจากเครือข่าย โดยเกมนี้คือการทำความเข้าใจว่า "สำคัญ" หมายถึงอะไรในบริบทนี้ วิธีการทั่วไปคือการวัดผลกระทบของฟังก์ชันการสูญเสียของแต่ละน้ำหนัก ซึ่งสามารถทำได้ง่ายโดยดูค่าอนุพันธ์อันดับหนึ่งและอันดับสองของฟังก์ชันการสูญเสีย วิธีอื่นคือการใช้การปรับให้เหมาะสม L1 หรือ L2 และกำจัดน้ำหนักที่มีขนาดเล็ก การลบเซลล์ประสาททั้งหมด ชั้น หรือตัวกรองเรียกว่า "การตัดแต่งแบบโครงสร้าง" (structured pruning) และมีประสิทธิภาพมากกว่าเมื่อใช้ความเร็วในการอนุมาน
การปรับแต่งโมเดล (Model quantization) คือการลดความแม่นยำของพารามิเตอร์ โดยทั่วไปจะเปลี่ยนจากลอยตัว (32 บิต) เป็นจำนวนเต็ม (8 บิต) ซึ่งเป็นการบีบอัดโมเดล 4 เท่า การปรับแต่งพารามิเตอร์มักทำให้โมเดลห่างจากจุดสิ้นสุด ดังนั้นจึงเป็นเรื่องปกติที่จะปรับแต่งโมเดลด้วยข้อมูลการฝึกอบรมเพิ่มเติมเพื่อรักษาความสามารถในการทำงานของโมเดลไว้ เรียกว่า "การฝึกอบรมแบบปรับแต่ง" (Quantization-aware training) เมื่อเราพยายามหลีกเลี่ยงขั้นตอนสุดท้ายนี้ เรียกว่า "การปรับแต่งหลังการฝึกอบรม" (Post training quantization) และสามารถทำการปรับแต่งน้ำหนักเพิ่มเติมเพื่อช่วยให้โมเดลมีประสิทธิภาพ
การแยกตัวประกอบอันดับต่ำ (Low-rank decomposition) มาจากข้อเท็จจริงที่ว่าเมทริกซ์น้ำหนักของเครือข่ายประสาทเทียมสามารถประมาณได้โดยผลคูณของเมทริกซ์ขนาดเล็ก เมทริกซ์ขนาด N x N สามารถแยกตัวประกอบได้เป็นผลคูณของ 2 เมทริกซ์ขนาด N x 1 ซึ่งเป็นการลดความซับซ้อนของพื้นที่จาก O(N^2) เป็น O(N)
การถ่ายทอดความรู้ (Knowledge distillation) คือการถ่ายทอดความรู้จากโมเดลหนึ่งไปยังอีกโมเดลหนึ่ง โดยทั่วไปจะถ่ายทอดจากโมเดลขนาดใหญ่ไปยังโมเดลขนาดเล็ก เมื่อโมเดลนักเรียนเรียนรู้เพื่อผลิตการตอบสนองที่คล้ายกัน นั่นคือการถ่ายทอดแบบการตอบสนอง (response-based distillation) เมื่อโมเดลนักเรียนเรียนรู้เพื่อทำซ้ำชั้นกลางที่คล้ายกัน นั่นคือการถ่ายทอดแบบคุณลักษณะ (feature-based distillation) เมื่อโมเดลนักเรียนเรียนรู้เพื่อทำซ้ำปฏิสัมพันธ์ระหว่างชั้น นั่นคือการถ่ายทอดแบบความสัมพันธ์ (relation-based distillation)
การออกแบบโมเดลแบบเบา (Lightweight model design) คือการใช้ความรู้จากผลลัพธ์เชิงประจักษ์เพื่อออกแบบโครงสร้างที่มีประสิทธิภาพมากขึ้น นี่อาจเป็นวิธีที่ใช้มากที่สุดในการวิจัยโมเดลภาษาขนาดใหญ่
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA