- เผยแพร่เมื่อ
OpenAi O1: เกณฑ์มาตรฐานที่ดีมาก
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
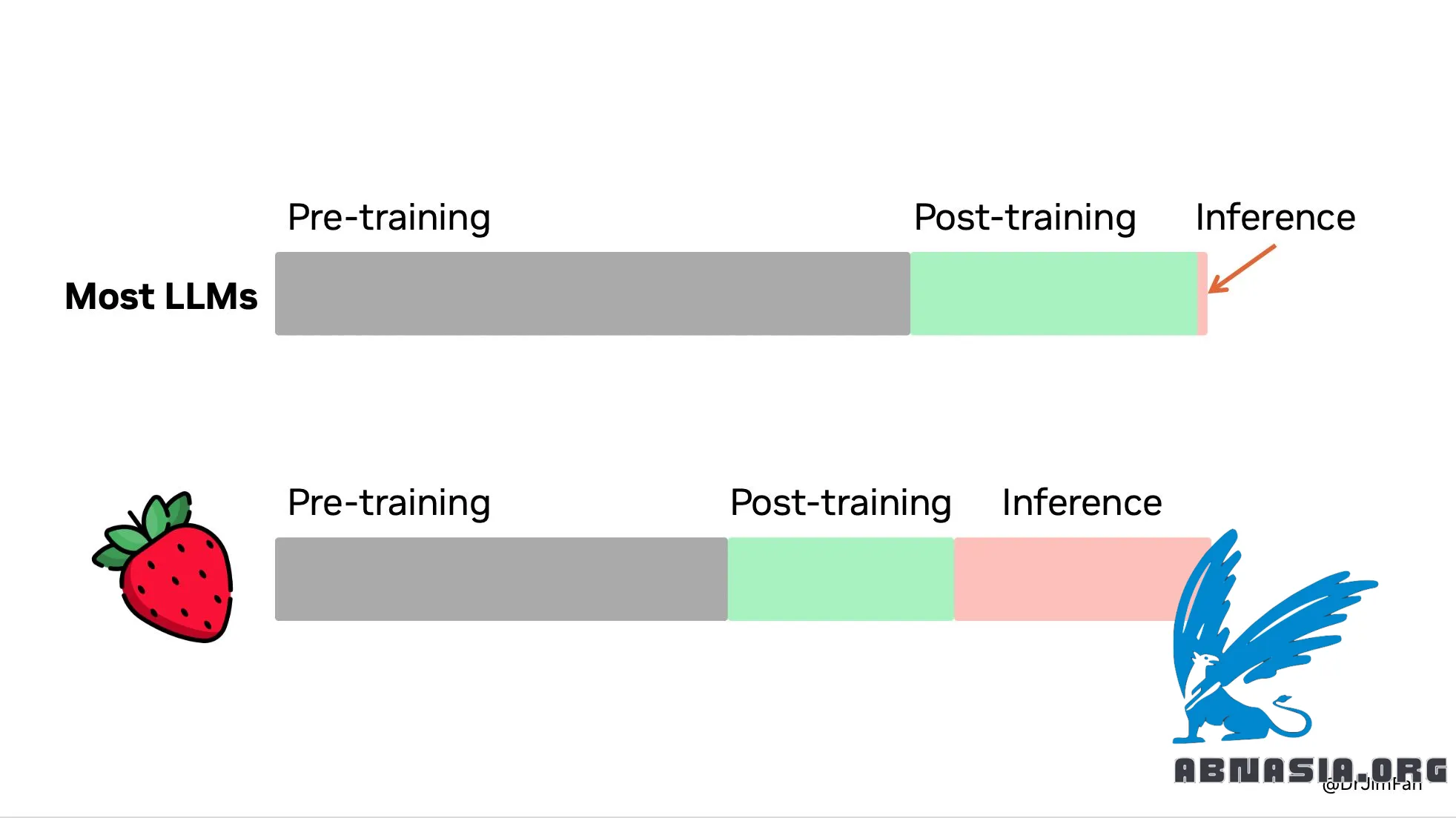
"OpenAI Strawberry (o1) ออกแล้ว! ในที่สุดเราก็เห็นกระบวนทัศน์ของการปรับขนาดเวลาอนุมานที่ได้รับความนิยมและนำไปใช้จริง ดังที่ซัตตันกล่าวไว้ในบทเรียน Bitter Lesson มีเพียง 2 เทคนิคเท่านั้นที่จะปรับขนาดอย่างไม่มีกำหนดด้วยการประมวลผล นั่นก็คือ การเรียนรู้และการค้นหา ถึงเวลาที่ต้องเปลี่ยนโฟกัสไปที่สิ่งหลัง
คุณไม่จำเป็นต้องมีแบบจำลองขนาดใหญ่ในการให้เหตุผล พารามิเตอร์จำนวนมากมีไว้สำหรับการจดจำข้อเท็จจริงโดยเฉพาะ เพื่อให้ทำงานได้ดีในเกณฑ์มาตรฐาน เช่น Trivia QA เป็นไปได้ที่จะแยกการให้เหตุผลออกจากความรู้ เช่น ""แกนการให้เหตุผล"" ขนาดเล็กที่รู้วิธีเรียกใช้เครื่องมือ เช่น เบราว์เซอร์และเครื่องมือตรวจสอบโค้ด การคำนวณก่อนการฝึกอาจลดลง
การประมวลผลจำนวนมากถูกเปลี่ยนไปใช้การอนุมานแทนก่อน/หลังการฝึกอบรม LLM เป็นตัวจำลองแบบข้อความ ด้วยการเปิดตัวกลยุทธ์และสถานการณ์ที่เป็นไปได้มากมายในเครื่องจำลอง ในที่สุดโมเดลก็จะมาบรรจบกันเป็นโซลูชันที่ดี กระบวนการนี้เป็นปัญหาที่ได้รับการศึกษามาอย่างดี เช่น การค้นหาต้นไม้มอนติคาร์โล (MCTS) ของ AlphaGo
OpenAI ต้องคิดกฎมาตราส่วนการอนุมานมาเป็นเวลานานแล้ว ซึ่งนักวิชาการเพิ่งค้นพบเมื่อไม่นานมานี้ เอกสารสองฉบับออกมาใน Arxiv ห่างกันหนึ่งสัปดาห์เมื่อเดือนที่แล้ว:
ลิงภาษาขนาดใหญ่: ปรับขนาดการคำนวณการอนุมานด้วยการสุ่มตัวอย่างซ้ำ บราวน์ และคณะ พบว่า DeepSeek-Coder เพิ่มขึ้นจาก 15.9% ด้วยหนึ่งตัวอย่างเป็น 56% ด้วย 250 ตัวอย่างบน SWE-Bench ซึ่งเอาชนะ Sonnet-3.5 ได้
การปรับขนาดการคำนวณเวลาทดสอบ LLM อย่างเหมาะสมจะมีประสิทธิภาพมากกว่าพารามิเตอร์โมเดลการปรับขนาด สเนลล์ และคณะ พบว่า PaLM 2-S เอาชนะโมเดลที่ใหญ่กว่า 14 เท่าใน MATH พร้อมการค้นหาเวลาทดสอบ
การผลิต o1 นั้นยากกว่าการบรรลุเกณฑ์มาตรฐานทางวิชาการมาก สำหรับการให้เหตุผลกับปัญหาในป่า จะตัดสินใจได้อย่างไรว่าเมื่อใดควรหยุดค้นหา? ฟังก์ชั่นการให้รางวัลคืออะไร? เกณฑ์ความสำเร็จ? เมื่อใดจึงควรเรียกใช้เครื่องมือเช่นล่ามโค้ดในลูป จะคำนึงถึงต้นทุนการประมวลผลของกระบวนการ CPU เหล่านั้นอย่างไร โพสต์การวิจัยของพวกเขาไม่ได้แชร์อะไรมากนัก
สตรอเบอร์รี่กลายเป็นมู่เล่ข้อมูลได้อย่างง่ายดาย หากคำตอบถูกต้อง การติดตามการค้นหาทั้งหมดจะกลายเป็นชุดข้อมูลขนาดเล็กของตัวอย่างการฝึกอบรม ซึ่งมีรางวัลทั้งเชิงบวกและเชิงลบ
ซึ่งจะช่วยปรับปรุงแกนหลักในการให้เหตุผลสำหรับ GPT เวอร์ชันในอนาคต เช่นเดียวกับวิธีที่เครือข่ายคุณค่าของ AlphaGo ที่ใช้ในการประเมินคุณภาพของแต่ละตำแหน่งบอร์ด ปรับปรุงเมื่อ MCTS สร้างข้อมูลการฝึกอบรมที่ละเอียดยิ่งขึ้นเรื่อยๆ"
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA