- เผยแพร่เมื่อ
ออพทิไมเซอร์คืออะไร และทำไมพวกมันถึงมีอยู่
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
เราทุกคนรู้ว่า ตัวปรับให้คำแนะนำในการเรียนรู้: ปรับพารามิเตอร์เพื่อลดฟังก์ชันความสูญเสีย ช่วยให้เครือข่ายประสาทเทียมเรียนรู้
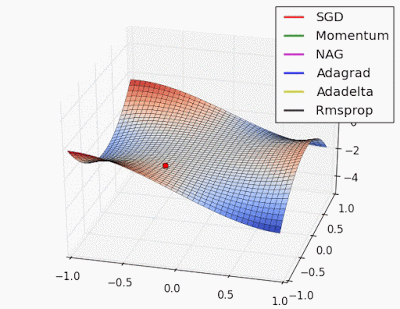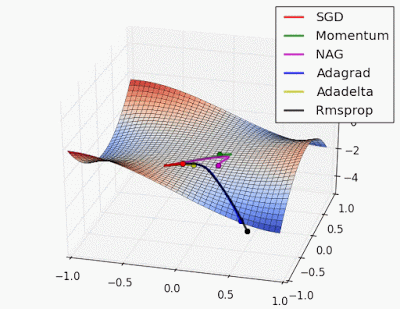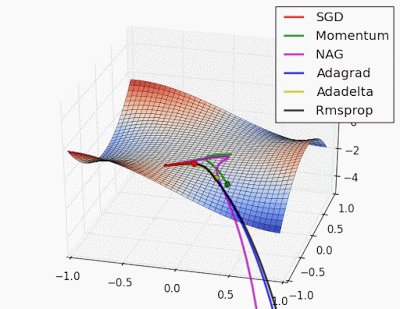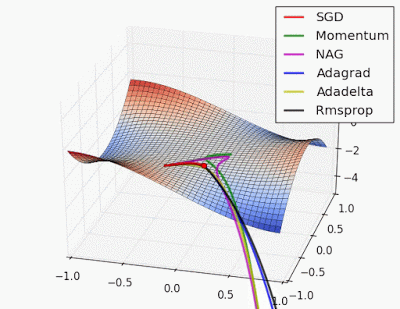
อะไรนะ? อธิบายแบบง่ายๆ ได้ไหม? 😀
ลองนึกภาพว่าคุณกำลังเดินทางไปเที่ยวกับเพื่อนๆ แต่คุณหลงทาง
พื้นที่เป็นเนินเขาและค่ำแล้ว แต่รถของคุณมี GPS 🚗
ลองนึกภาพว่า Optimizer เป็น GPS ของรถของคุณ 🛰️
เหมือนกับ GPS ที่ช่วยให้คุณไปถึงจุดหมายได้ด้วยเส้นทางที่เร็วที่สุดหรือราบรื่นที่สุด Optimizer ก็ช่วยให้กระบวนการฝึกอบรมไปสู่ค่า Loss ที่ต่ำกว่า (จุดหมาย)
Optimizer พื้นฐาน เช่น Simple Gradient Descent เหมือนกับการขับรถโดยใช้แผนที่เส้นทางพื้นฐาน: อาจจะไปถึงจุดหมายได้ แต่อาจจะไปผิดทาง (ไม่มีการอัปเดตแบบเรียลไทม์ การเสียหายของถนน ฯลฯ)
ในขณะที่ Adaptive Optimizer เช่น Adam หรือ RMSProp เหมือนกับ GPS ที่หรูหรา ซึ่งปรับให้เหมาะสมกับอุปสรรคในแบบเรียลไทม์และเลือกเส้นทางที่มีประสิทธิภาพเพื่อไปถึงจุดหมายได้เร็วขึ้น
หากไม่มี GPS คุณอาจจะใช้เวลานานในการเดินทางในเส้นทางที่ไม่รู้จัก 🚫 ในทำนองเดียวกัน หากไม่มี Optimizer การฝึกอบรมแบบจำลองจะใช้เวลานานและยากลำบากในการเรียนรู้จากข้อมูลอย่างมีประสิทธิภาพ
แต่ทำไมจึงมีตัวเลือกมากมาย?
ก่อนอื่น มาทำความเข้าใจกันว่าปัญหาอะไรที่ Optimizer ช่วยแก้ไข:
1️⃣ การค้นหาพื้นที่น้ำหนักอย่างมีประสิทธิภาพ - การฝึกอบรมแบบจำลองประสาทเทียมหมายถึงการเดินทางผ่านภูมิประเทศที่ซับซ้อนและไม่เป็นเชิงเส้น (เนินเขา) ของน้ำหนัก และเป้าหมายคือการหาค่าผสมที่ลด Loss
2️⃣ การลู่เข้าอย่างมั่นคงและเชื่อถือได้ - ในระหว่างการฝึกอบรม แบบจำลองอาจ "ติด" ในค่าต่ำสุดเฉพาะที่ หรือน้ำหนักอาจสั่นไหวโดยไม่ลู่เข้า Optimizer ช่วยจัดการกับความท้าทายเหล่านี้
แต่ทำไมจึงมีตัวเลือกมากมาย?
เรื่องราวเริ่มต้นเมื่อหลายปีที่แล้ว โดยเริ่มแรกพัฒนาเพื่อแก้ไขปัญหาการเพิ่มประสิทธิภาพทางคณิตศาสตร์
Gradient Descent (GD) มาจากกลางศตวรรษที่ 19 (นานขนาดนั้นจริงๆ) จากนั้นจึงมี Stochastic Gradient Descent (SGD) และ Mini Batch GD - แม้ว่าจะมีประสิทธิภาพ แต่ก็มีข้อจำกัด โดยเฉพาะอย่างยิ่งเกี่ยวกับความเร็วในการลู่เข้าและเสถียรภาพในข้อมูลที่ซับซ้อน
เพื่อแก้ไขปัญหเหล่านี้ นักวิจัยได้พัฒนา Optimizer ที่ซับซ้อนมากขึ้น ซึ่งปรับอัตราการเรียนรู้หรือใช้โมเมนตัมเพื่อจัดการกับเกรเดียนต์ที่แตกต่างกันอย่างมีประสิทธิภาพ
จากนั้นจึงมี Momentum-based Optimizer (เช่น SGD with Momentum) -> Adaptive Optimizer (เช่น AdaGrad, RMSProp) -> Adam (การรวมกันของโมเมนตัมและวิธีการปรับตัว) -> และวิธีการใหม่ๆ (เช่น AdamW, LAMB และ Lion) ที่แก้ไขความท้าทายในการฝึกอบรมเฉพาะ
Optimizer ใหม่ๆ จะยังคงเกิดขึ้น โดยแต่ละตัวได้รับการออกแบบเพื่อแก้ไขความท้าทายเฉพาะ เช่น เสถียรภาพในการฝึกอบรม ประสิทธิภาพ หรือการปรับตัวให้เข้ากับโครงสร้างใหม่ๆ บางตัวจะกลายเป็นมาตรฐาน บางตัวจะหายไป และบางตัวจะยืนยงไปกับเวลา แต่จุดประสงค์หลักของ Optimizer คือการช่วยให้กระบวนการฝึกอบรมมีประสิทธิภาพและประสิทธิผล
อ้อ สุดท้าย เมื่อไม่แน่ใจ ให้ใช้ Adam 😀
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA