- เผยแพร่เมื่อ
รูปแบบภาษาขนาดใหญ่ทำงานอย่างไร
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
แผนภาพด้านล่างแสดงสถาปัตยกรรมหลักของ LLMs
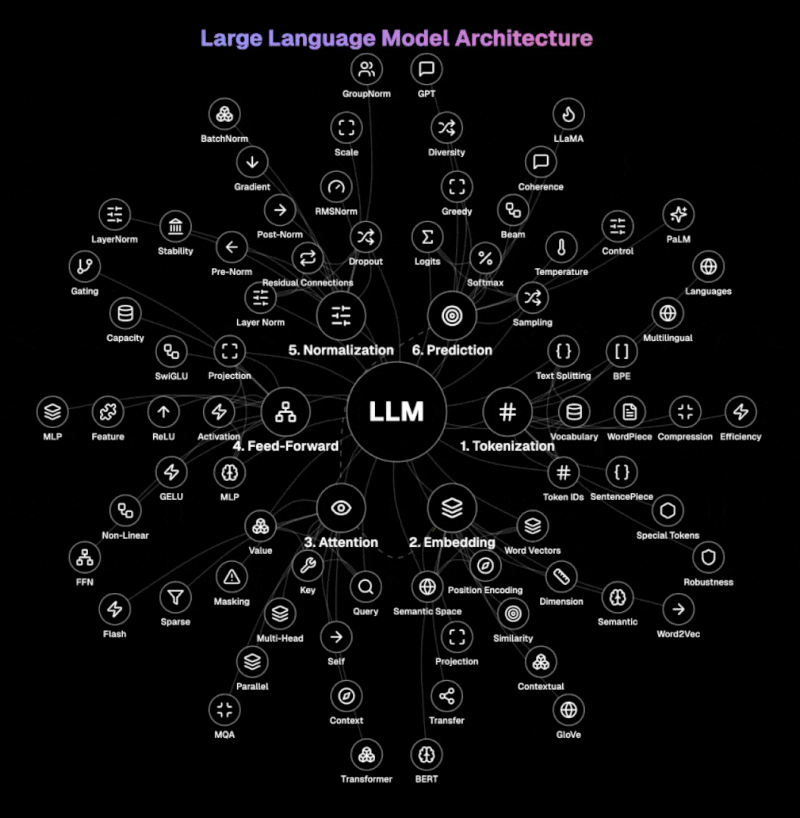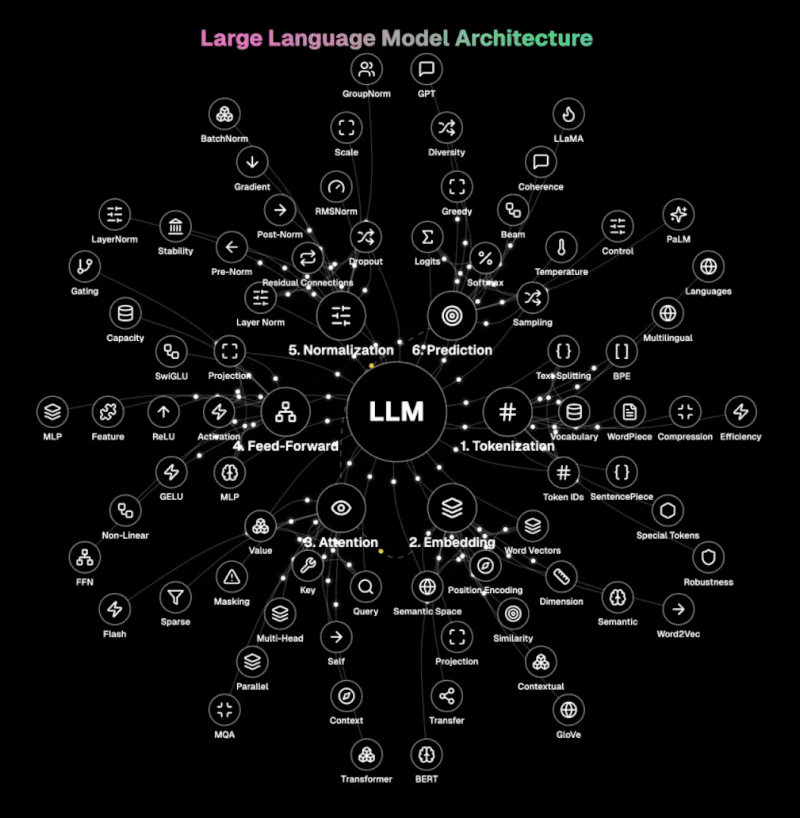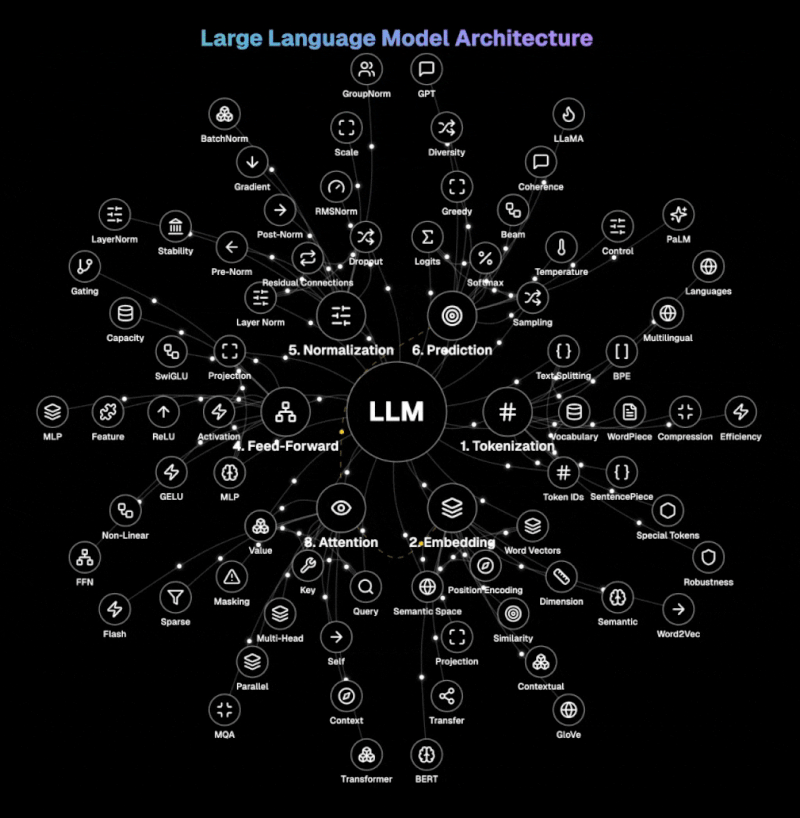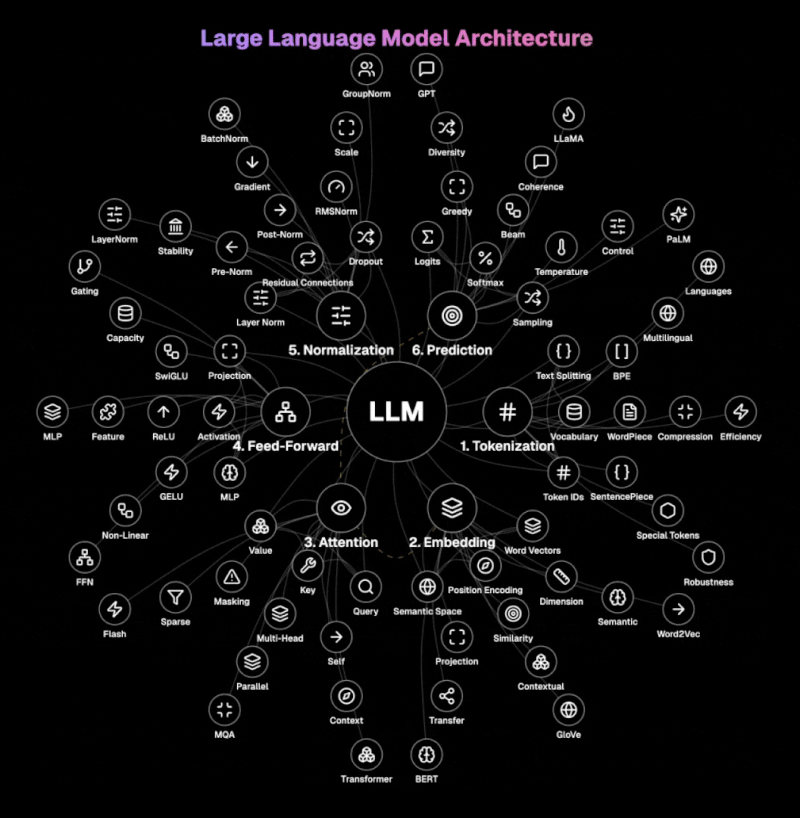
ขั้นตอนที่ 1: การแบ่งคำ โมเดล LLM แบ่งข้อความออกเป็นหน่วยที่จัดการได้เรียกว่า โทเค็น (token) โดยใช้เทคนิค เช่น BPE, WordPiece หรือ SentencePiece จัดการคำ, ส่วนคำ หรืออักขระ โพรเซสนี้แปลงภาษาธรรมชาติเป็น ID โทเค็นที่โมเดลสามารถประมวลผลได้ โดยมีโทเค็นพิเศษที่ทำเครื่องหมายเริ่มต้น, สิ้นสุด หรือฟังก์ชันพิเศษภายในข้อความ ขนาดว็อคาเบอรี่และเทคนิคการบีบอัดโทเค็นมีความสำคัญต่อการประมวลผลที่มีประสิทธิภาพ
ขั้นตอนที่ 2: การฝังตัว ชั้นนี้แปลง ID โทเค็นที่ไม่ต่อเนื่องกันเป็นตัวแทนเวกเตอร์ที่มีความอุดมสมบูรณ์ในพื้นที่เชิงสำนวนที่มีมิติสูง โดยรวมเวกเตอร์คำเข้ากับการเข้ารหัสตำแหน่งเพื่อรักษาข้อมูลลำดับ เมทริกซ์ฝังตัวจับความสัมพันธ์เชิงความหมายระหว่างคำ ทำให้แนวคิดที่คล้ายกันอยู่ใกล้กันในพื้นที่เวกเตอร์
ขั้นตอนที่ 3: การจัดความสนใจ หัวใจของโมเดล LLM รุ่นใหม่ การจัดความสนใจกำหนดส่วนใดของอินพุตที่จะเน้นเมื่อสร้างโทเคนอินพุตแต่ละตัว โดยใช้เวกเตอร์แบบสอบถาม, คีย์ และค่า มันคำนวณคะแนนความเกี่ยวข้องระหว่างโทเค็นทั้งหมดในลำดับ การจัดความสนใจหลายหัวประมวลผลข้อมูลแบบขนานข้ามพื้นที่แสดงภาพย่อยต่างๆ โดยจับความสัมพันธ์ต่างๆ ในเวลาเดียวกัน การจัดความสนใจด้วยตนเองทำให้โมเดลพิจารณาบริบททั้งหมดเมื่อประมวลผลแต่ละโทเค็น
ขั้นตอนที่ 4: การป้อนไปข้างหน้า ส่วนประกอบนี้แปลงการแสดงถึงโทเค็นแต่ละตัวอิสระผ่านตัว感知หลายชั้น (MLP) โดยใช้ฟังก์ชันการกระตุ้นที่ไม่เป็นเชิงเส้น เช่น GELU หรือ ReLU เพื่อนำเสนอความซับซ้อนที่จับได้จากรูปแบบที่ละเอียดอ่อนในข้อมูล โครงข่ายป้อนไปข้างหน้าเพิ่มความสามารถของโมเดลในการแสดงถึงฟังก์ชันและความสัมพันธ์ที่ซับซ้อน มันประมวลผลการแสดงถึงโทเค็นแต่ละตัว โดยเสริมการประมวลผลบริบทของกลไกการจัดความสนใจ
ขั้นตอนที่ 5: การปรับมาตรฐาน การปรับมาตรฐานชั้นมาตรฐานอินพุตข้ามคุณลักษณะ ในขณะที่การเชื่อมต่อที่เหลือให้ข้อมูลไหลผ่านเครือข่ายได้โดยตรง สถาปัตยกรรม pre-norm และ post-norm มีผลกระทบต่อเสถียรภาพและประสิทธิภาพที่แตกต่างกัน การหยุดชั่วคราวป้องกันการปรับให้เหมาะสมมากเกินไปโดยการปิดใช้งานนิวรอนแบบสุ่มระหว่างการฝึกอบรม ทำให้โมเดลพัฒนาการแสดงถึงที่ซ้ำซ้อน
ขั้นตอนที่ 6: การทำนาย ขั้นตอนสุดท้ายแปลงการแสดงถึงที่ประมวลผลเป็นความน่าจะเป็นเหนือว็อคาเบอรี่ มันสร้างลอจิต (คะแนนดิบ) สำหรับโทเค็นถัดไปที่เป็นไปได้แต่ละตัว ซึ่งแปลงเป็นความน่าจะเป็นโดยใช้ฟังก์ชัน softmax การสุ่มตัวอย่างอุณหภูมิควบคุมความสุ่มในการสร้าง โดยมีอุณหภูมิต่ำกว่าผลิตเอาต์พุตที่แน่นอนมากขึ้น กลยุทธ์การถอดรหัส เช่น การค้นหาแบบ貪婪, การค้นหาแบบลำดับ หรือการสุ่มตัวอย่างนิวเคลียส กำหนดว่าโมเดลเลือกโทเค็นระหว่างการสร้างอย่างไร
สิ่งที่ทำให้โมเดล LLM แตกต่างจากระบบประมวลผลภาษาทางเดิมคือธรรมชาติแบบอัตโนมัติ ซึ่งสร้างกระบวนการสร้างแบบขั้นตอนแทนการสร้างคำตอบทั้งหมดในครั้งเดียว
ในมุมมองของคุณ: ส่วนประกอบทางสถาปัตยกรรมใดที่ทำให้เกิดการเห็นภาพหลอกลวงในโมเดล LLM
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องกรทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA