- Xuất bản vào
4 chiến lược đào tạo đa GPU giải thích bằng hình ảnh.
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Mặc định, các mô hình học sâu chỉ sử dụng một GPU để đào tạo, ngay cả khi có nhiều GPU có sẵn. Đây là một mẹo.
Cách lý tưởng để tiếp tục (đặc biệt là trong các cài đặt dữ liệu lớn) là phân phối khối lượng công việc đào tạo trên nhiều GPU.
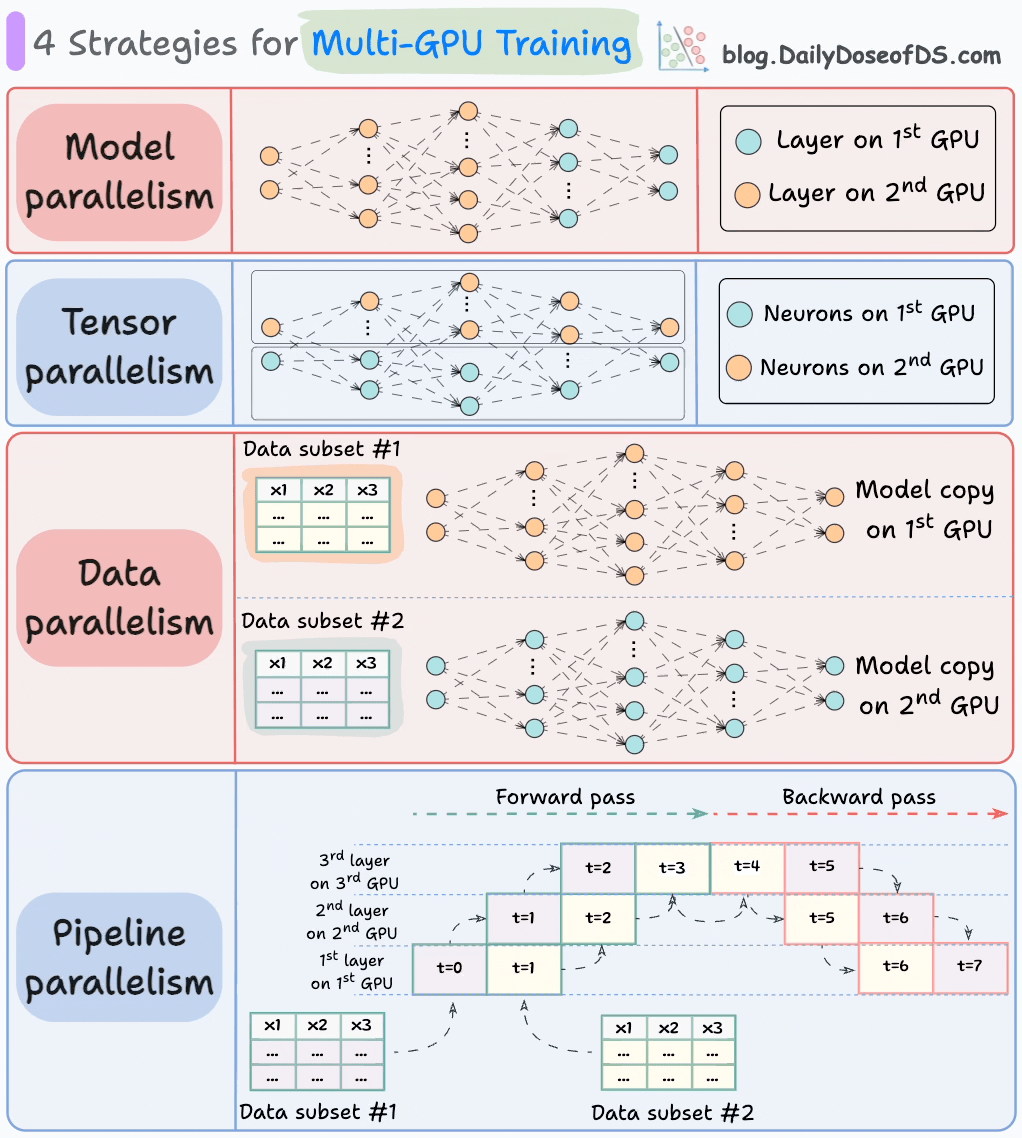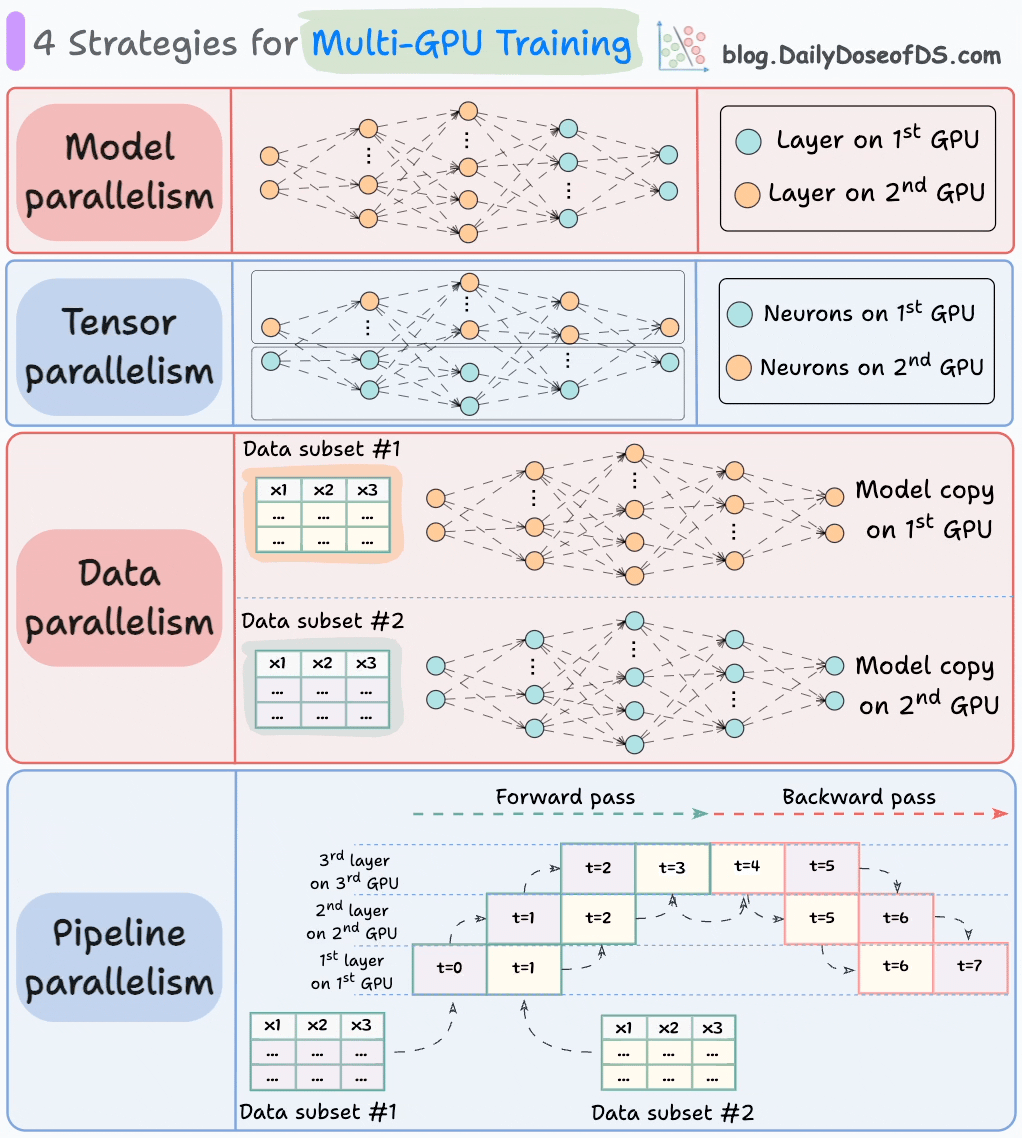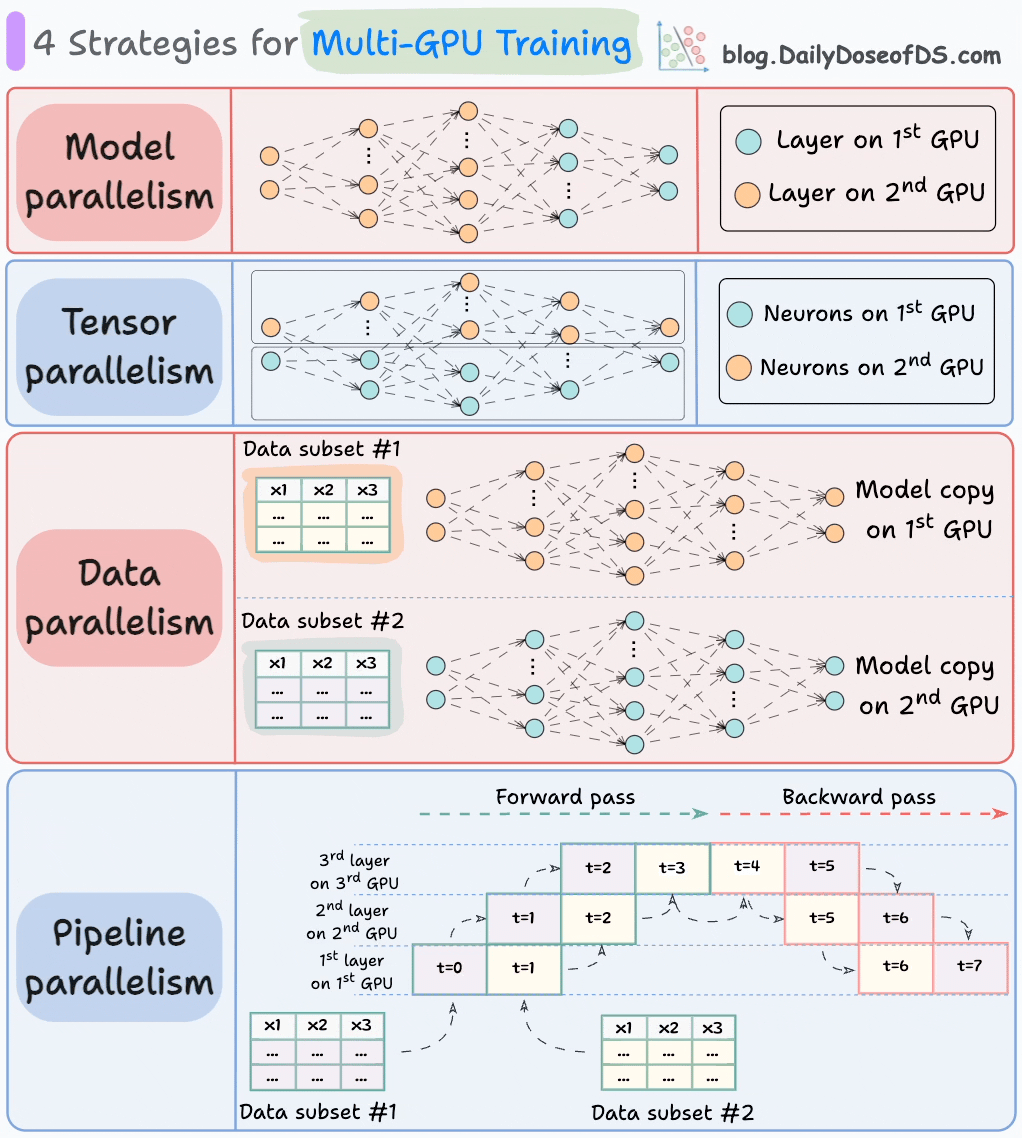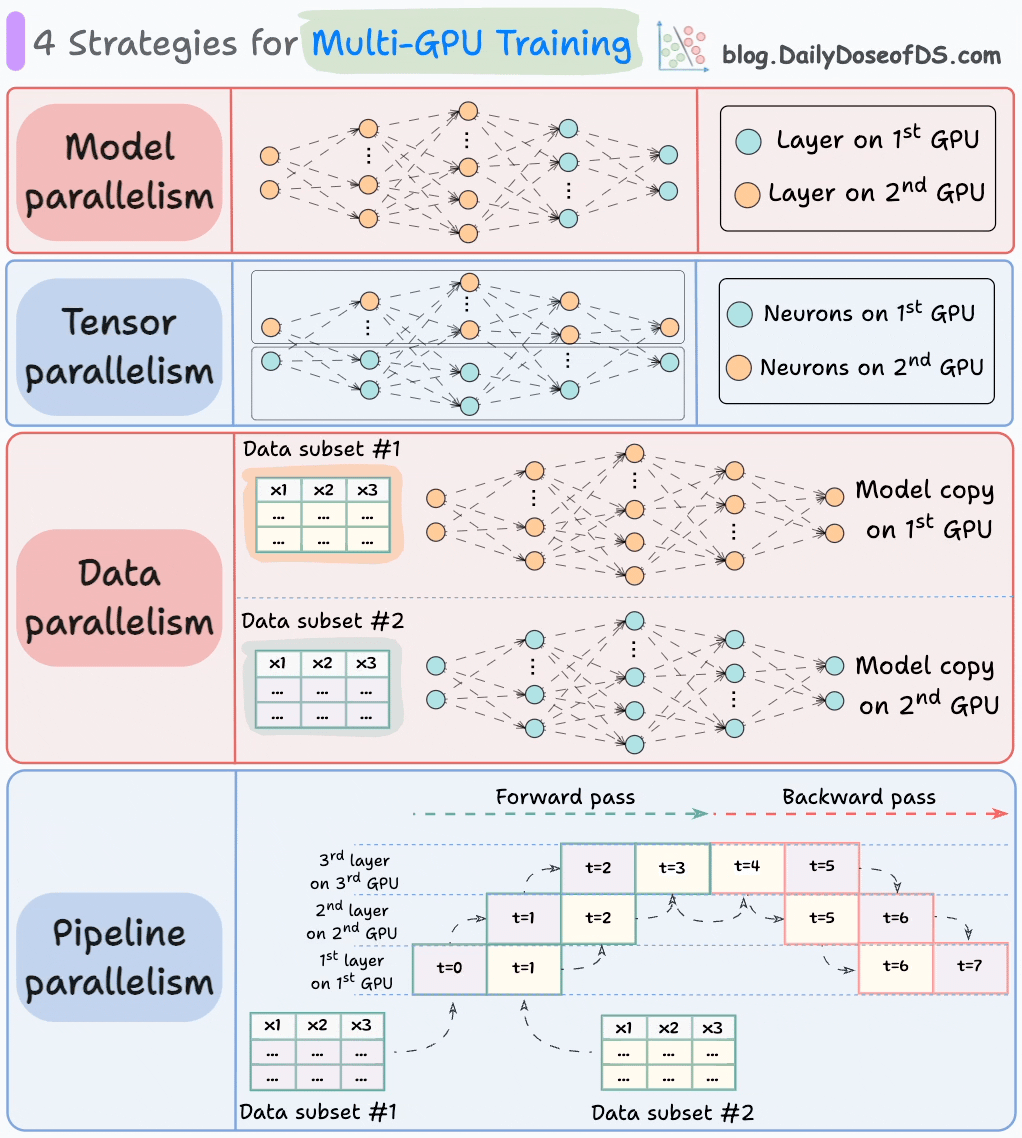
Biểu đồ dưới đây mô tả bốn chiến lược phổ biến cho đào tạo nhiều GPU:
- Song song hóa mô hình
- Các phần khác nhau (hoặc lớp) của mô hình được đặt trên các GPU khác nhau.
- Có ích cho các mô hình khổng lồ không phù hợp trên một GPU duy nhất.
- Tuy nhiên, song song hóa mô hình cũng giới thiệu các nút thắt nghiêm trọng vì nó yêu cầu luồng dữ liệu giữa các GPU khi các hoạt động từ một GPU được chuyển sang một GPU khác.
- Song song hóa tensor
- Phân phối và xử lý các hoạt động tensor riêng lẻ trên nhiều thiết bị hoặc bộ xử lý.
- Nó dựa trên ý tưởng rằng một hoạt động tensor lớn, chẳng hạn như nhân ma trận, có thể được chia thành các hoạt động tensor nhỏ hơn và mỗi hoạt động nhỏ hơn có thể được thực hiện trên một thiết bị hoặc bộ xử lý riêng biệt.
- Các chiến lược song song hóa này vốn có được tích hợp vào các triển khai tiêu chuẩn của PyTorch và các khung học sâu khác, nhưng chúng trở nên rõ ràng hơn trong một cài đặt phân tán.
- Song song hóa dữ liệu
- Sao chép mô hình trên tất cả các GPU.
- Chia dữ liệu có sẵn thành các lô nhỏ hơn và mỗi lô được xử lý bởi một GPU riêng biệt.
- Các bản cập nhật (hoặc gradient) từ mỗi GPU sau đó được tổng hợp và sử dụng để cập nhật các tham số mô hình trên mọi GPU.
- Song song hóa đường ống
Điều này thường được coi là sự kết hợp của song song hóa dữ liệu và song song hóa mô hình.
Vấn đề với song song hóa mô hình tiêu chuẩn là GPU đầu tiên vẫn ở chế độ không hoạt động khi dữ liệu đang được truyền qua các lớp có sẵn trên GPU thứ hai:
Song song hóa đường ống giải quyết điều này bằng cách tải lô dữ liệu vi mô tiếp theo một khi GPU đầu tiên đã hoàn thành các tính toán trên lô dữ liệu vi mô đầu tiên và chuyển các hoạt động sang các lớp có sẵn trên GPU thứ hai.
Quá trình trông giống như sau:
↳ Lô dữ liệu vi mô đầu tiên đi qua các lớp trên GPU đầu tiên.
↳ GPU thứ hai nhận được các hoạt động trên lô dữ liệu vi mô đầu tiên từ GPU đầu tiên.
↳ Trong khi GPU thứ hai truyền dữ liệu qua các lớp, một lô dữ liệu vi mô khác được tải trên GPU đầu tiên.
↳ Và quá trình tiếp tục.
- Sử dụng GPU được cải thiện đáng kể theo cách này. Điều này rõ ràng từ hoạt ảnh dưới đây nơi nhiều GPU đang được sử dụng tại cùng một dấu thời gian (xem t=1, t=2, t=5 và t=6).
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA