- Xuất bản vào
Các Mô Hình Học Máy: Phương Pháp Nén Mô Hình
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Tại sao? Bởi vì bây giờ chúng quá lớn.
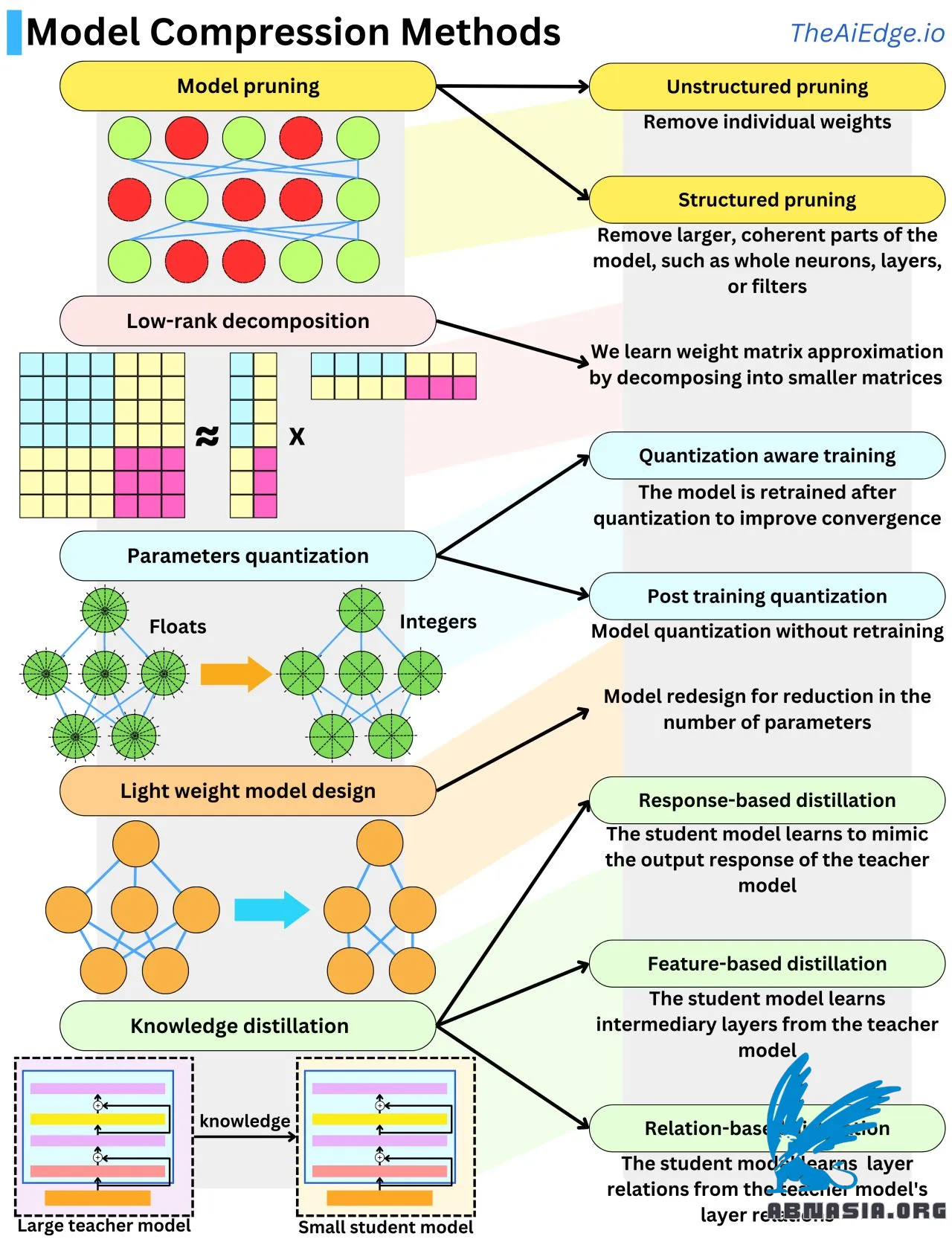
Không lâu trước đây, các mô hình Học Máy lớn nhất mà hầu hết mọi người sẽ xử lý chỉ đạt đến vài GB trong kích thước bộ nhớ. Bây giờ, mỗi mô hình sinh mới ra đều nằm trong khoảng từ 1 tỷ đến 1 nghìn tỷ tham số! Để có cảm giác về quy mô, một tham số float, đó là 32 bit hoặc 4 byte (hoặc 2 byte với Float16), vì vậy những mô hình mới này có thể mở rộng từ 4 GB đến 4 TB trong bộ nhớ, mỗi cái chạy trên phần cứng đắt tiền. Và trong thuật toán lan truyền ngược, những mô hình này có thể cần đến gấp 10 lần lượng bộ nhớ này. Do sự gia tăng quy mô khổng lồ, đã có khá nhiều nghiên cứu để giảm kích thước mô hình trong khi vẫn giữ hiệu suất cao. Có 5 kỹ thuật chính để nén kích thước mô hình.
Cắt tỉa mô hình là việc loại bỏ các trọng số không quan trọng khỏi mạng. Trò chơi là hiểu "quan trọng" có nghĩa là gì trong ngữ cảnh đó. Một cách tiếp cận điển hình là đo lường tác động lên hàm mất mát của mỗi trọng số. Điều này có thể được thực hiện dễ dàng bằng cách nhìn vào gradient và đạo hàm bậc hai của hàm mất mát. Một cách khác để làm điều này là sử dụng điều chỉnh L1 hoặc L2 và loại bỏ các trọng số có độ lớn thấp. Loại bỏ toàn bộ neuron, lớp, hoặc bộ lọc được gọi là "cắt tỉa có cấu trúc" và hiệu quả hơn khi nói đến tốc độ suy luận.
Lượng tử hóa mô hình là việc giảm độ chính xác của tham số, thường bằng cách chuyển từ float (32 bit) sang số nguyên (8 bit). Đó là nén mô hình 4 lần. Lượng tử hóa các tham số có xu hướng làm cho mô hình lệch khỏi điểm hội tụ của nó, vì vậy thường phải tinh chỉnh nó với dữ liệu đào tạo bổ sung để giữ hiệu suất mô hình cao. Chúng tôi gọi đây là "Đào tạo nhận thức lượng tử hóa". Khi chúng tôi tránh bước cuối cùng này, nó được gọi là "Lượng tử hóa sau đào tạo", và có thể thực hiện các sửa đổi dựa trên kinh nghiệm bổ sung cho các trọng số để giúp cải thiện hiệu suất.
Phân rã hạng thấp xuất phát từ thực tế là ma trận trọng số mạng nơ-ron có thể được xấp xỉ bằng tích của các ma trận có kích thước thấp. Một ma trận N x N có thể được phân rã xấp xỉ thành tích của 2 ma trận N x 1. Đó là một lợi ích độ phức tạp không gian O(N^2) -> O(N)!
Chưng cất tri thức là việc chuyển giao tri thức từ một mô hình sang một mô hình khác, thường là từ một mô hình lớn sang một mô hình nhỏ hơn. Khi mô hình học sinh học cách tạo ra các phản hồi đầu ra tương tự, đó là chưng cất dựa trên phản hồi. Khi mô hình học sinh học cách tái tạo các lớp trung gian tương tự, nó được gọi là chưng cất dựa trên đặc điểm. Khi mô hình học sinh học cách tái tạo sự tương tác giữa các lớp, nó được gọi là chưng cất dựa trên quan hệ.
Thiết kế mô hình nhẹ là việc sử dụng kiến thức từ kết quả thực nghiệm để thiết kế các kiến trúc hiệu quả hơn. Đó có lẽ là một trong những phương pháp được sử dụng nhiều nhất trong nghiên cứu LLM.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA