- Xuất bản vào
Các Mô Hình Ngôn Ngữ Lớn Hoạt Động Như Thế Nào?
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Sơ đồ dưới đây minh họa kiến trúc cốt lõi của LLMs.
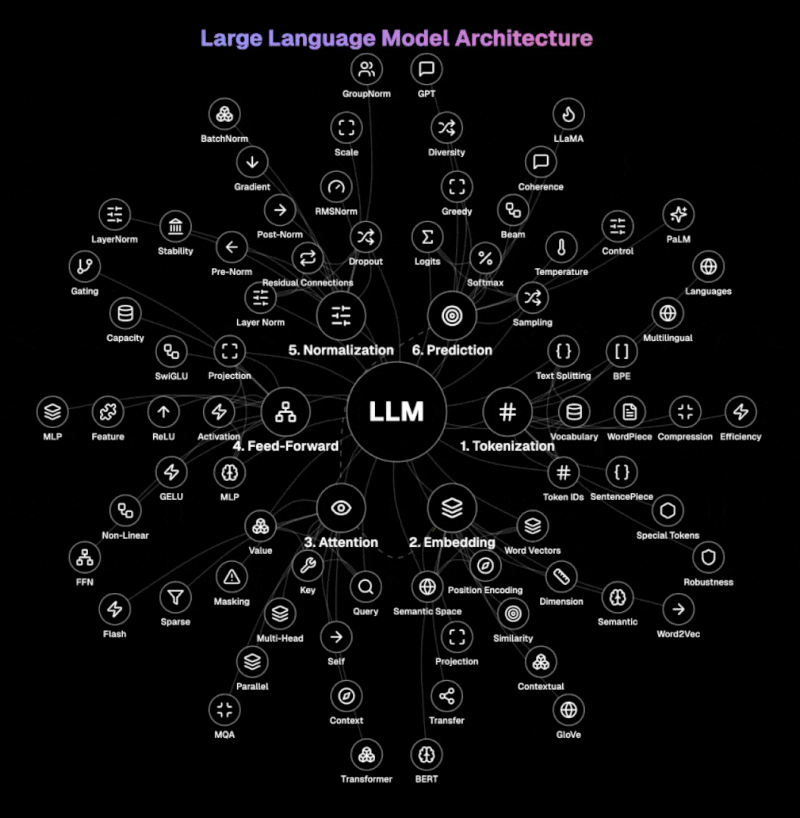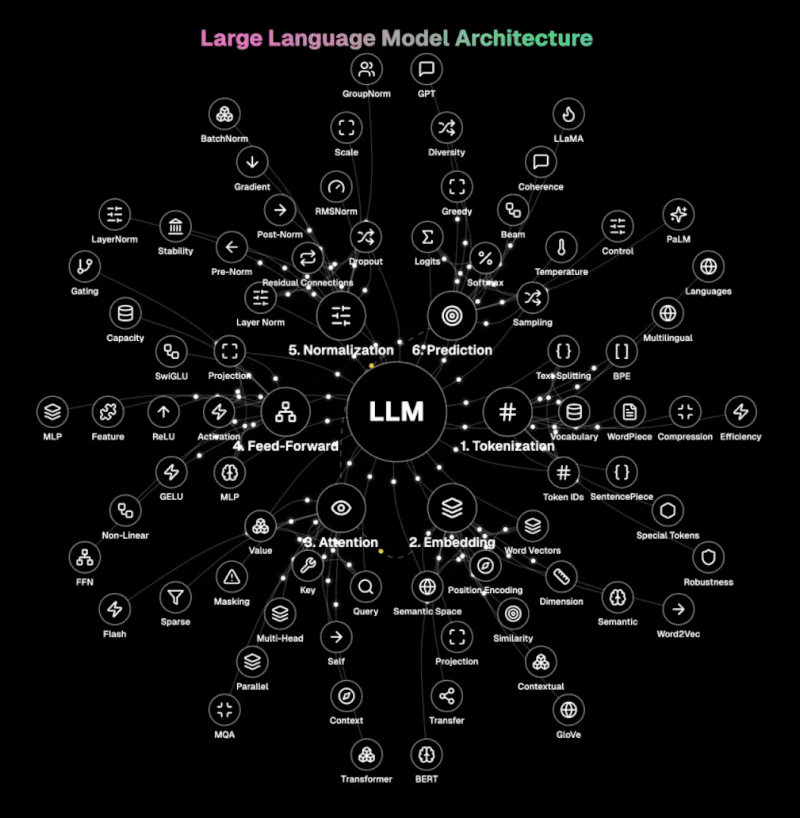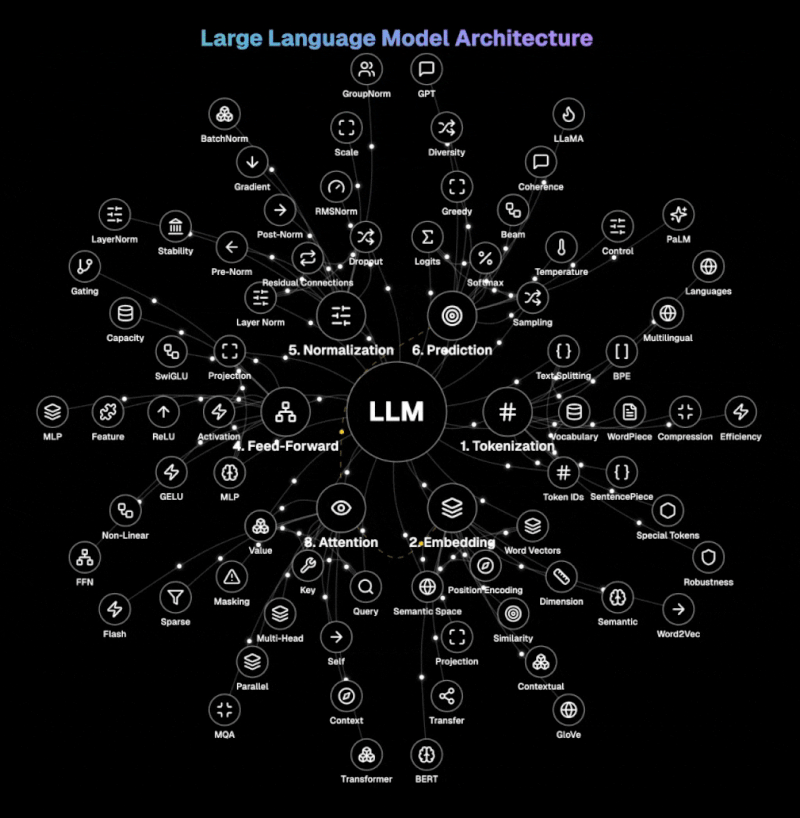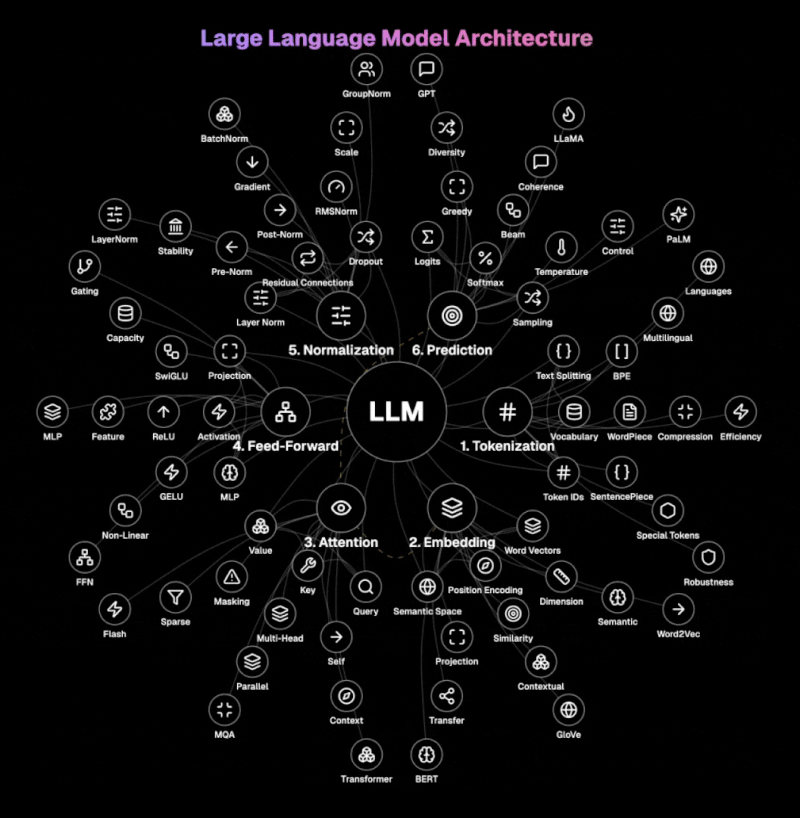
Bước 1: Phân đoạn LLM phân chia văn bản thành các đơn vị có thể quản lý được gọi là token. Nó xử lý từ, từ con, hoặc ký tự bằng các kỹ thuật như BPE, WordPiece, hoặc SentencePiece. Quá trình này chuyển đổi ngôn ngữ tự nhiên thành các ID token mà mô hình có thể xử lý, với các token đặc biệt đánh dấu sự bắt đầu, kết thúc, hoặc các chức năng đặc biệt trong văn bản. Kích thước từ vựng và các kỹ thuật nén token là rất quan trọng để xử lý hiệu quả.
Bước 2: Nhúng Lớp này chuyển đổi các ID token rời rạc thành các biểu diễn vector phong phú trong không gian ngữ nghĩa nhiều chiều. Nó kết hợp vector từ với mã hóa vị trí để bảo toàn thông tin thứ tự. Ma trận nhúng nắm bắt các mối quan hệ ngữ nghĩa giữa các từ, cho phép các khái niệm tương tự tồn tại gần nhau trong không gian vector.
Bước 3: Chú ý Trái tim của các LLM hiện đại, chú ý xác định phần nào của đầu vào cần tập trung khi tạo ra mỗi token đầu ra. Sử dụng các vector truy vấn, khóa, và giá trị, nó tính toán điểm liên quan giữa tất cả các token trong chuỗi. Chú ý đa đầu xử lý thông tin song song qua các không gian biểu diễn khác nhau, nắm bắt các mối quan hệ khác nhau cùng lúc. Chú ý tự cho phép mô hình xem xét toàn bộ ngữ cảnh khi xử lý mỗi token.
Bước 4: Truyền tiếp Thành phần này biến đổi biểu diễn của mỗi token một cách độc lập thông qua một mạng perceptron nhiều lớp (MLP). Nó áp dụng các hàm kích hoạt phi tuyến tính như GELU hoặc ReLU để giới thiệu sự phức tạp nắm bắt các mẫu tinh tế trong dữ liệu. Mạng truyền tiếp tăng khả năng của mô hình để biểu diễn các hàm và mối quan hệ phức tạp. Nó xử lý các biểu diễn token một cách riêng lẻ, bổ sung cho quá trình xử lý ngữ cảnh của cơ chế chú ý.
Bước 5: Chuẩn hóa Chuẩn hóa lớp tiêu chuẩn hóa đầu vào qua các đặc trưng, trong khi các kết nối dư cho phép thông tin chảy trực tiếp qua mạng. Kiến trúc tiền chuẩn và hậu chuẩn cung cấp các sự đánh đổi giữa độ ổn định và hiệu suất khác nhau. Dropout ngăn chặn quá khớp bằng cách ngẫu nhiên vô hiệu hóa các neuron trong quá trình huấn luyện, buộc mô hình phát triển các biểu diễn dư thừa.
Bước 6: Dự đoán Bước cuối cùng chuyển đổi các biểu diễn đã xử lý thành xác suất trên từ vựng. Nó tạo ra logits (điểm thô) cho mỗi token tiếp theo có thể, được chuyển đổi thành xác suất bằng cách sử dụng hàm softmax. Lấy mẫu nhiệt độ kiểm soát sự ngẫu nhiên trong việc tạo ra, với nhiệt độ thấp hơn tạo ra các đầu ra quyết định hơn. Các chiến lược giải mã như tham lam, tìm kiếm chùm, hoặc lấy mẫu hạt nhân xác định cách mô hình chọn token trong quá trình tạo ra.
Điều làm cho LLM khác biệt với các hệ thống xử lý ngôn ngữ truyền thống là tính chất tự hồi quy của chúng. Điều này tạo ra một quá trình tạo ra từng bước thay vì tạo ra toàn bộ phản hồi cùng một lúc.
Theo quan điểm của bạn: Thành phần kiến trúc nào gây ra ảo giác trong LLM?
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA