- Xuất bản vào
Học máy: Sự kết hợp của kiến trúc chuyên gia
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Ngày nay, bạn chớp mắt và có 20 kỹ thuật hoặc công cụ Machine Learning mới mà bạn cần tìm hiểu! Kiến trúc Hỗn hợp các Chuyên gia hoàn toàn không phải là một kỹ thuật mới, nhưng giờ đây nó đã trở thành chiến lược mặc định để mở rộng quy mô LLM. Tôi nhớ đã đọc về nó vài năm trước và coi nó là ""một bài báo LLM khác có lẽ không quan trọng"". Vâng, bây giờ nó quan trọng! Hầu hết các LLM lớn hơn đều có khả năng sử dụng chiến lược đó trong tương lai!
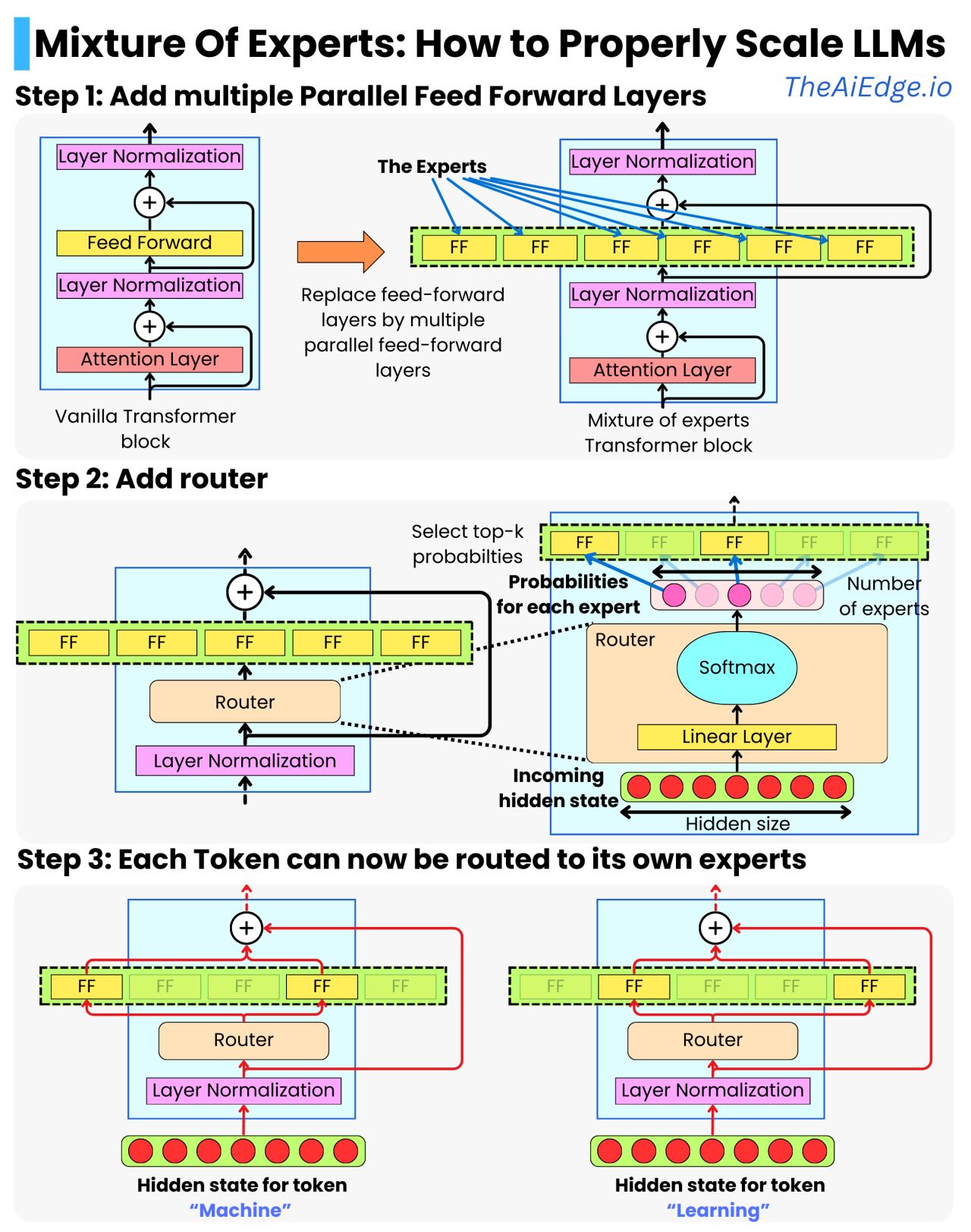
Khối biến áp điển hình là sự nối tiếp của lớp chú ý, lớp chuẩn hóa, lớp chuyển tiếp tiếp liệu và lớp chuẩn hóa khác. Chiến lược mở rộng quy mô máy biến áp là chỉ cần thêm nhiều khối máy biến áp lần lượt. Ý tưởng của MoE là mở rộng quy mô ""theo chiều ngang"" bằng cách thêm nhiều lớp chuyển tiếp song song hơn trong mỗi khối. Đó là những chuyên gia.
Trước lớp chuyên gia, chúng tôi thêm một bộ định tuyến để mỗi mã thông báo chỉ đi qua một vài chuyên gia. Ví dụ: chúng ta có thể có 64 chuyên gia, nhưng với trạng thái ẩn của mã thông báo chỉ trải qua 2 trong số đó. Điều này đảm bảo việc học tập đa dạng đồng thời giảm thiểu tải tính toán và do đó giảm độ trễ tại thời điểm suy luận.
Bộ định tuyến chỉ là một lớp tuyến tính có trạng thái ẩn và tạo ra một vectơ có nhiều mục nhập như các chuyên gia. Bằng cách sử dụng phép biến đổi softmax, chúng ta có được xác suất cho từng chuyên gia. Bây giờ chúng ta có thể sử dụng những xác suất đó để chọn ra các chuyên gia hàng đầu và xây dựng mức trung bình có trọng số về kết quả đầu ra của các chuyên gia được chọn. Ví dụ: nếu chúng ta lấy 2 chuyên gia hàng đầu:
trạng thái mới = P(FFN_1) * FFN_1 (trạng thái ẩn) + P(FFN_2) * FFN_2 (trạng thái ẩn)
Ngay cả khi chỉ có 2 chuyên gia hàng đầu, trạng thái ẩn đầu ra mới có thể thể hiện một tập hợp thông tin phong phú hơn nhiều được học bởi các tổ hợp chuyên gia khác nhau. Điều này cũng cung cấp một cách rất tự nhiên để phân phối các tính toán mô hình trên nhiều máy GPU. Mỗi máy có thể chứa nhiều chuyên gia và việc tính toán của các chuyên gia khác nhau có thể diễn ra song song trên các máy khác nhau.
Tuy nhiên, việc đào tạo mô hình MoE không hề đơn giản vì nó gây ra nhiều bất ổn trong đào tạo. Một khó khăn là đảm bảo mỗi chuyên gia nhìn thấy đủ dữ liệu để tìm hiểu các mẫu thống kê có liên quan. Chiến lược điển hình là thêm một thuật ngữ vào hàm mất để cung cấp tải dữ liệu cân bằng giữa các chuyên gia.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA