- Xuất bản vào
Tại sao chúng ta cứ nói về token trong LLM thay vì lời nói?
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Tại sao chúng ta cứ nói về "mã thông báo" trong LLM thay vì words? Sẽ hiệu quả hơn nhiều nếu chia các từ thành các từ phụ (mã thông báo) để đạt hiệu suất cao hơn cho mô hình!
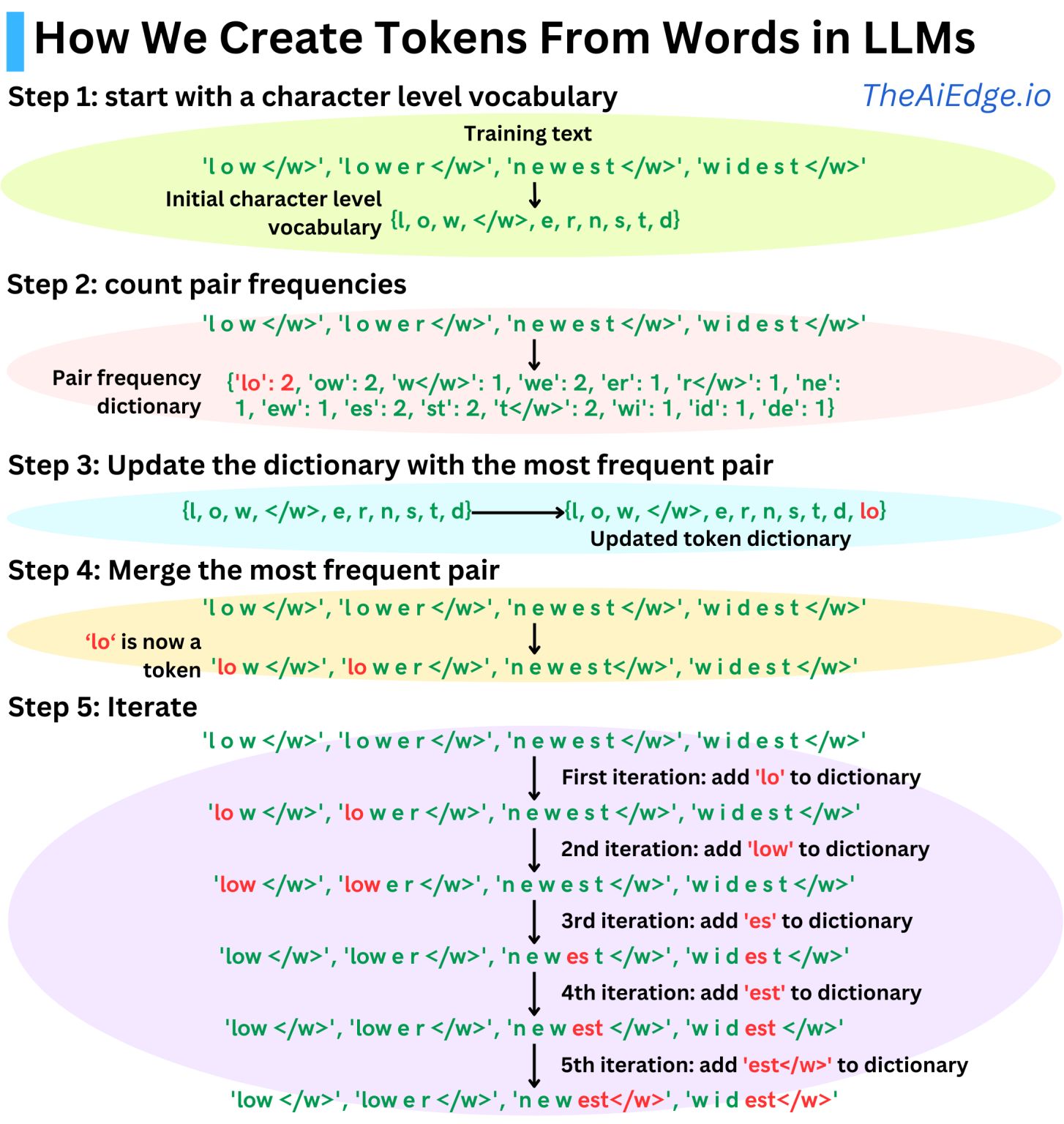
Chiến lược điển hình được sử dụng trong hầu hết các LLM hiện đại kể từ GPT-1 là chiến lược Mã hóa cặp byte (BPE). Ý tưởng là sử dụng các đơn vị từ phụ xuất hiện thường xuyên trong dữ liệu huấn luyện làm mã thông báo. Các thuật toán hoạt động như sau:
Chúng ta bắt đầu với mã thông báo cấp ký tự
Chúng ta đếm tần số cặp
Chúng ta hợp nhất cặp thường xuyên nhất
Chúng ta lặp lại quá trình này cho đến khi từ điển đủ lớn như mong muốn
Kích thước của từ điển trở thành một siêu tham số mà chúng ta có thể điều chỉnh dựa trên dữ liệu huấn luyện của mình. Ví dụ: GPT-1 có kích thước từ điển ~40K hợp nhất, GPT-2, GPT-3 và ChatGPT có kích thước từ điển ~50K và Llama 3 128K.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA