- Xuất bản vào
Tăng cường LLM bằng cơ sở dữ liệu là điều tuyệt vời, nhưng cách tiếp cận đó có những sai sót lớn!
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
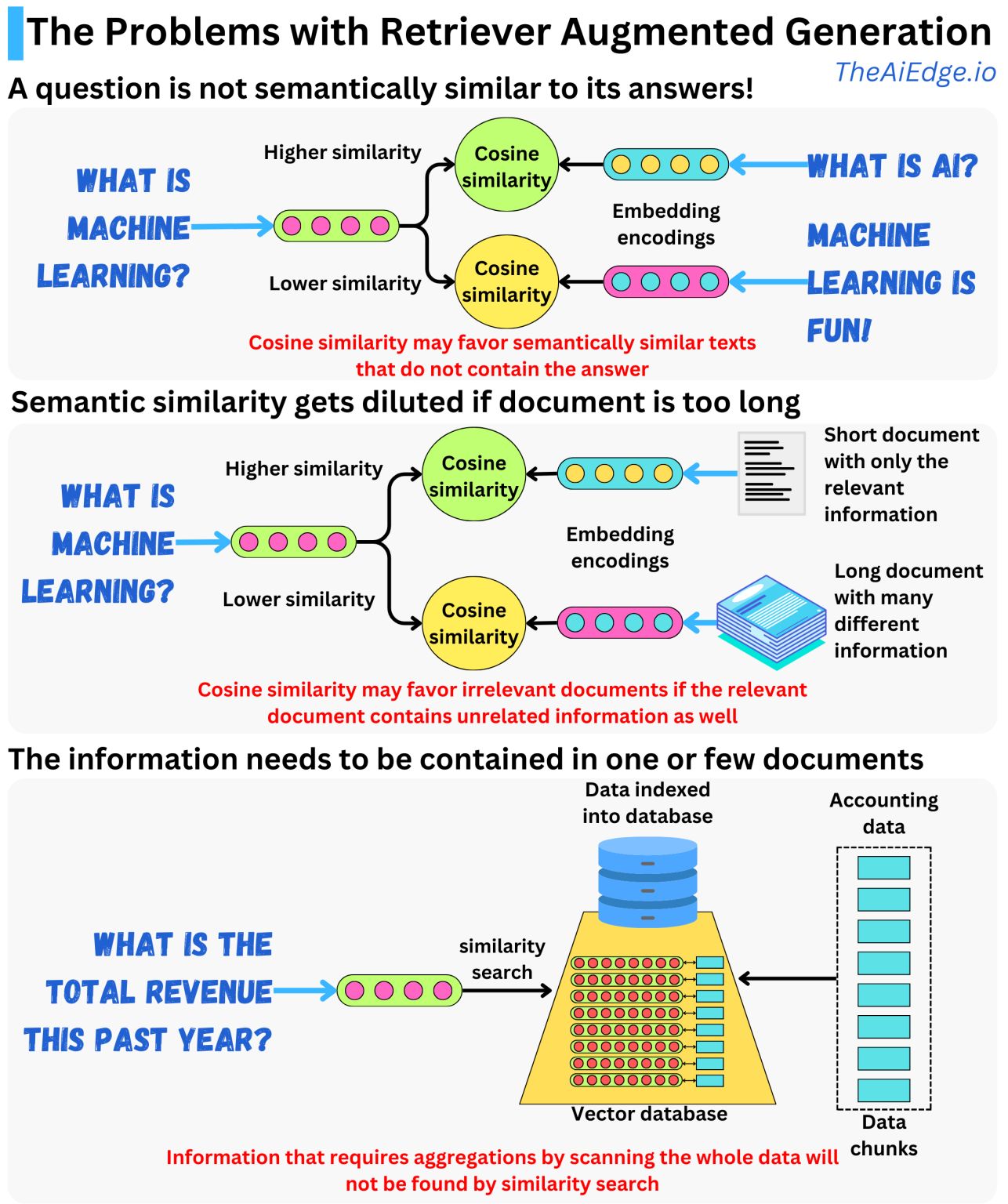
Ý tưởng với RAG là mã hóa dữ liệu bạn muốn hiển thị cho LLM của mình thành các phần nhúng và lập chỉ mục dữ liệu đó vào cơ sở dữ liệu vectơ. Khi người dùng đặt câu hỏi, câu hỏi đó sẽ được chuyển thành nội dung nhúng và chúng tôi có thể sử dụng nó để tìm kiếm các nội dung nhúng tương tự trong cơ sở dữ liệu. Sau khi tìm thấy các phần nhúng tương tự, chúng tôi sẽ tạo lời nhắc với dữ liệu liên quan để cung cấp ngữ cảnh cho LLM trả lời câu hỏi. Độ tương tự ở đây thường được đo bằng thước đo độ tương tự cosine.
Vấn đề đầu tiên là một câu hỏi thường không giống về mặt ngữ nghĩa với câu trả lời của nó. Ít nhất, việc tìm kiếm có thể truy xuất các tài liệu chứa các từ giống với câu hỏi hoặc được sử dụng trong cùng ngữ cảnh mà không cung cấp thông tin liên quan để trả lời câu hỏi. Bởi vì tìm kiếm truy xuất các tài liệu giống nhất với câu hỏi, tùy thuộc vào dữ liệu, quá nhiều tài liệu không liên quan có thể hiển thị độ tương tự cosin cao hơn các tài liệu thực sự chứa câu trả lời.
Công bằng mà nói, độ tương tự cosine cao không chuyển chính xác thành sự tương đồng về ngữ nghĩa với Transformers. Độ tương tự cosine cao cũng có thể nắm bắt được sự xuất hiện cao của 2 thuật ngữ khác nhau trong cùng một văn bản phụ của dữ liệu huấn luyện, điều này thường xảy ra đối với một câu hỏi cụ thể và câu trả lời liên quan đến nó.
Một vấn đề khác có thể liên quan đến cách dữ liệu được lập chỉ mục. Nếu dữ liệu được chia thành các đoạn văn bản lớn thì nó có thể chứa nhiều thông tin khác nhau và không liên quan trong mỗi đoạn. Nếu bạn thực hiện tìm kiếm tương tự trên dữ liệu đó, thông tin thích hợp có thể bị giảm sút và thay vào đó, tìm kiếm có thể trả về các tài liệu không liên quan. Điều quan trọng là phải chia nhỏ dữ liệu sao cho mỗi đoạn chứa không quá một vài đoạn văn để đảm bảo tính duy nhất hơn trong các khái niệm được phát triển trong mỗi văn bản.
Với cách tiếp cận RAG, điều rất quan trọng là hạn chế loại câu hỏi mà chúng tôi hỏi LLM. Nếu chúng tôi đặt câu hỏi yêu cầu tổng hợp dữ liệu trên toàn bộ cơ sở dữ liệu, rất có thể câu trả lời sẽ sai nhưng LLM sẽ không thể biết điều đó. Nếu thông tin phù hợp nằm cục bộ trong một hoặc một vài tài liệu thì việc tìm kiếm tương tự có thể tìm thấy thông tin đó. Tuy nhiên, nếu thông tin yêu cầu quét tất cả các tài liệu để tìm câu trả lời thì tìm kiếm tương tự sẽ không tìm thấy. Hãy tưởng tượng mỗi tài liệu đều có niên đại và chúng tôi hỏi: "Tài liệu sớm nhất là gì?". Trong trường hợp đó, chúng tôi chỉ có thể biết câu trả lời nếu quét toàn bộ cơ sở dữ liệu và việc tìm kiếm điểm tương đồng sẽ không hữu ích.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA