- Xuất bản vào
Trình tối ưu hóa là gì và tại sao chúng lại tồn tại?
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Chúng ta đều biết rằng, các bộ tối ưu hóa hướng dẫn quá trình học: Chúng điều chỉnh các tham số để giảm thiểu hàm mất mát, giúp mạng nơ-ron học tập.
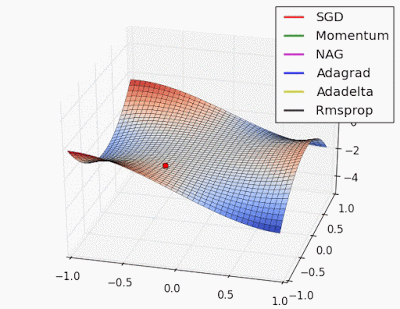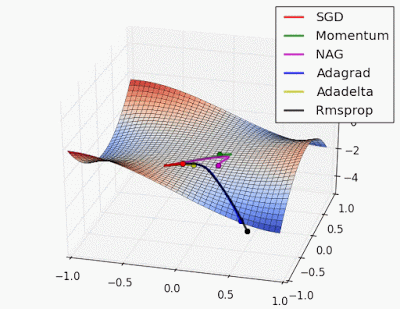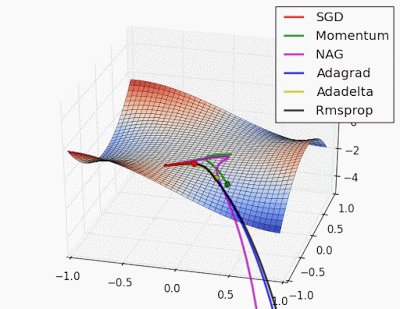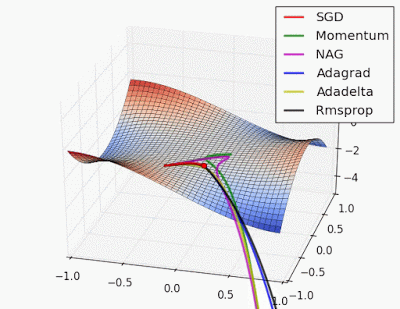
Gì? Bạn có thể giải thích đơn giản hơn không.😀
Hãy tưởng tượng bạn đang đi du lịch với bạn bè và bị lạc.
Địa hình đồi núi và trời tối. May mắn thay, xe của bạn có GPS.🚗
Hãy nghĩ về các bộ tối ưu hóa như GPS của xe bạn. 🛰️
Giống như GPS hướng dẫn bạn đến đích theo lộ trình nhanh nhất hoặc mượt mà nhất có thể, các bộ tối ưu hóa hướng dẫn quá trình huấn luyện đến các giá trị mất mát thấp hơn (đích đến).
Một bộ tối ưu hóa cơ bản, như gradient descent đơn giản, giống như lái xe với bản đồ lộ trình cơ bản: có thể cuối cùng bạn sẽ đến đó nhưng có thể dẫn đến các đường vòng (không có cập nhật thời gian thực, hỏng đường v.v.).
Trong khi các bộ tối ưu hóa thích ứng, như Adam hoặc RMSProp, giống như một GPS cao cấp, điều chỉnh cho các chướng ngại vật thời gian thực và chọn các con đường hiệu quả để đến đích nhanh hơn.
Không có GPS, bạn có thể mất hàng giờ để điều hướng các tuyến đường không quen thuộc. 🚫Tương tự, không có bộ tối ưu hóa, việc huấn luyện một mô hình sẽ là một quá trình dài và khó khăn, khó học từ dữ liệu một cách hiệu quả.
Nhưng tại sao có nhiều lựa chọn như vậy?
Được rồi, hãy hiểu trước những vấn đề mà các bộ tối ưu hóa giải quyết:
1️⃣ Tìm kiếm không gian trọng số hiệu quả - Huấn luyện một mạng nơ-ron nghĩa là điều hướng một cảnh quan không lồi phức tạp (địa hình đồi núi) của các trọng số và mục tiêu là tìm ra sự kết hợp đó để giảm thiểu mất mát.
2️⃣ Hội tụ ổn định và đáng tin cậy - Trong quá trình huấn luyện, các mô hình có thể bị "kẹt" trong các cực tiểu địa phương, hoặc các trọng số có thể dao động mà không hội tụ. Các bộ tối ưu hóa giúp quản lý những thách thức này.
Nhưng, tại sao lại có nhiều như vậy?
Câu chuyện bắt đầu từ rất lâu, ban đầu được phát triển để giải quyết các vấn đề tối ưu hóa trong toán học.
Gradient Descent (GD) có từ giữa thế kỷ 19 (thật lâu, phải không?), sau đó là Stochastic Gradient Descent (SGD) & Mini Batch GD - Mặc dù hiệu quả, chúng có những hạn chế, đặc biệt là về tốc độ hội tụ và ổn định trên dữ liệu phức tạp.
Để giải quyết những vấn đề này, các nhà nghiên cứu đã phát triển các bộ tối ưu hóa tinh vi hơn điều chỉnh tốc độ học hoặc sử dụng động lượng để xử lý các gradient khác nhau hiệu quả hơn.
Sau đó là các bộ tối ưu hóa dựa trên động lượng (như SGD với Momentum) -> Các bộ tối ưu hóa thích ứng (như AdaGrad, RMSProp) -> Adam (kết hợp phương pháp động lượng và thích ứng) -> và các phương pháp mới hơn (như AdamW, LAMB, và Lion) giải quyết các thách thức huấn luyện cụ thể.
Các bộ tối ưu hóa mới sẽ tiếp tục xuất hiện, mỗi cái được thiết kế để giải quyết các thách thức cụ thể, như sự ổn định huấn luyện, hiệu quả, hoặc thích ứng với các kiến trúc mới hơn. Một số sẽ trở thành xu hướng chính, một số sẽ phai nhạt, và một số sẽ đứng vững theo thời gian. Nhưng mục đích cốt lõi của chúng—hướng dẫn quá trình huấn luyện một cách hiệu quả và hiệu quả—vẫn không thay đổi.
À. Một điều cuối cùng. Khi nghi ngờ, chỉ cần sử dụng Adam 😀
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA