- Xuất bản vào
Xếp hạng Chatbot: Nhiệm vụ khác nhau, người chiến thắng khác nhau
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
Không nhiều người biết rằng Chatbot Arena công bố xếp hạng theo danh mục cho các lời nhắc như Toán học, Lập trình hoặc Viết sáng tạo cũng như điều chỉnh cho phong cách.
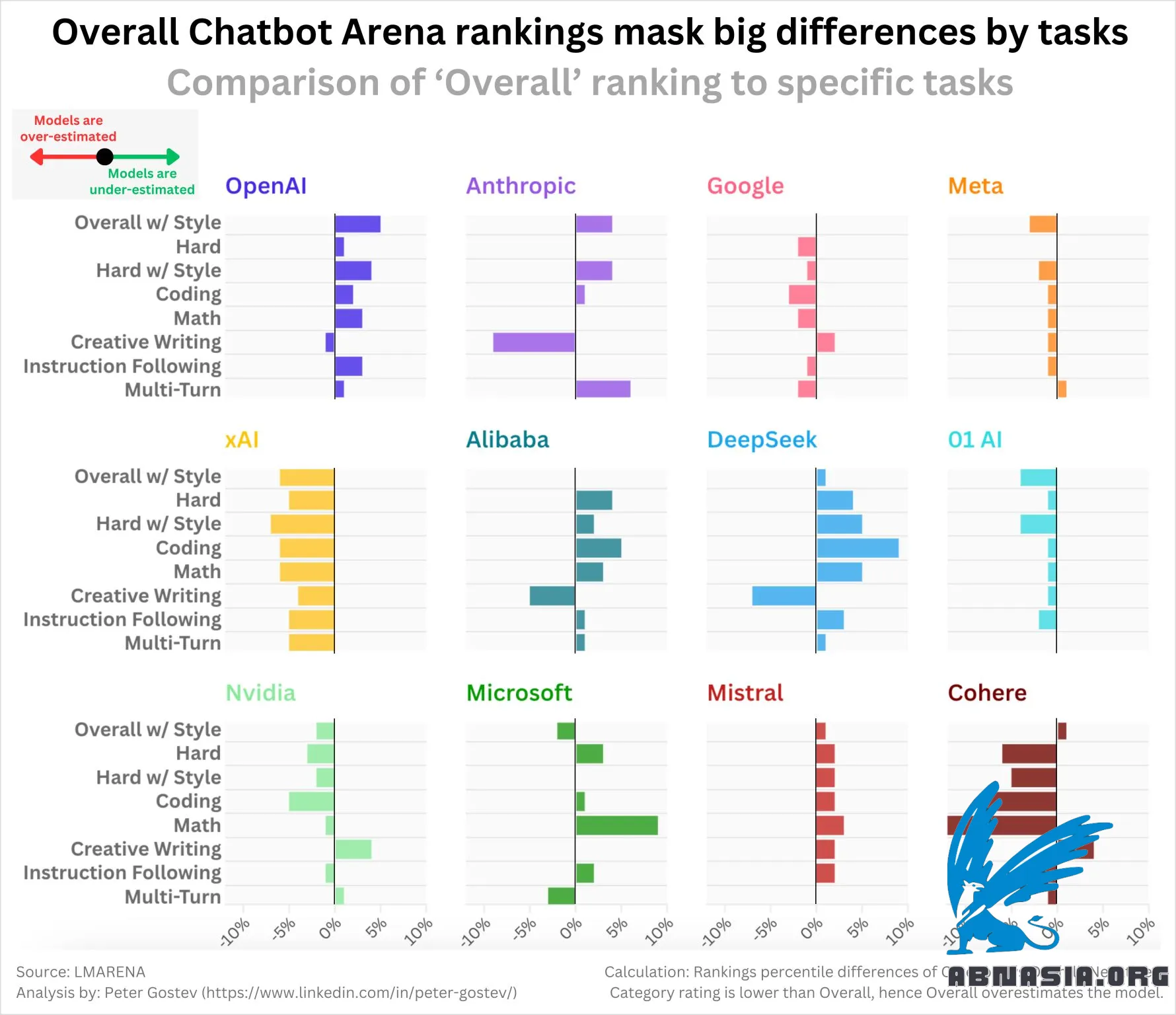
Điều này có nghĩa là chúng ta có thể thấy hiệu suất 'cốt lõi' của mô hình cho các nhiệm vụ nhất định.
Tôi đã quan tâm đến việc khám phá liệu các phòng thí nghiệm nhất định có xu hướng bị đánh giá thấp hoặc cao hơn so với xếp hạng 'Tổng thể' cho các nhiệm vụ khác nhau hay không. Kết quả thực sự không hoàn toàn như tôi mong đợi:
Các mô hình của OpenAI chủ yếu bị đánh giá thấp (tức là chúng mạnh hơn nếu bạn nhìn vào các xếp hạng cá nhân)
xAI, Google, Meta, 01 (phòng thí nghiệm, không phải mô hình), Cohere, Nvidia đều bị đánh giá cao
DeepSeek, Mistral, Alibaba (các mô hình Qwen) bị đánh giá thấp
Anthropic có sự pha trộn - đánh giá cao cho viết sáng tạo là khá thú vị
Như một mẹo, nếu bạn muốn xem các mô hình tốt nhất, tôi đề nghị nhìn vào 'Khó với Kiểm soát Phong cách' - nơi Sonnet 3.6, o1-preview, và Google-Exp-1121 cùng đứng đầu - nó phù hợp với trực giác của tôi về những mô hình tốt nhất hơn nhiều.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA