- Published on
Top 10 important data science concepts
- Authors

- Name
- AbnAsia.org
- @steven_n_t
Understand these concepts so you can have a common vocabulary with the data scientists.
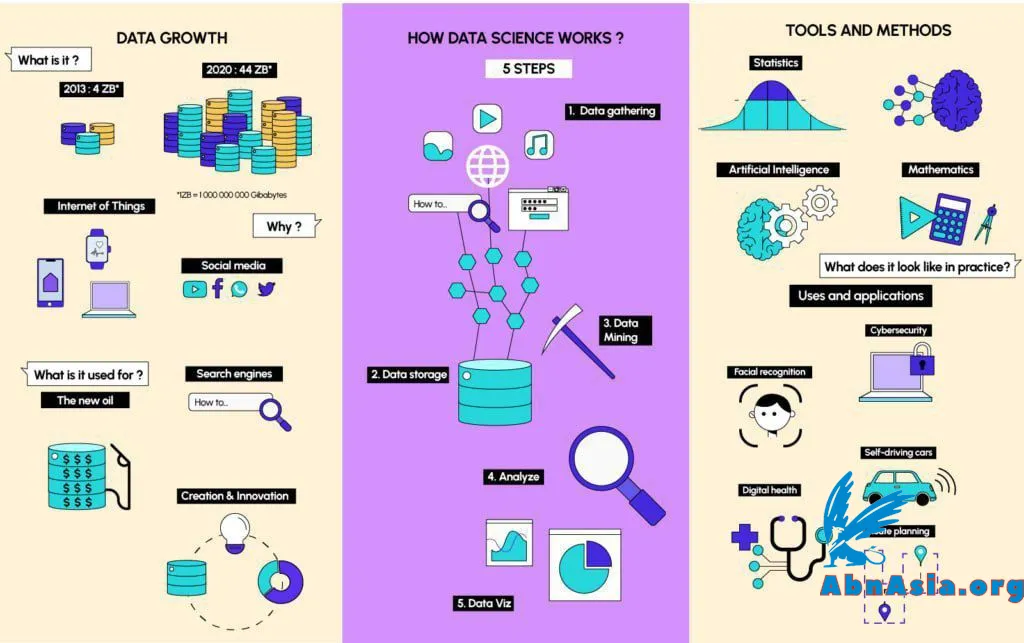
Data Cleaning: Data cleaning is the process of identifying and correcting or removing errors, inconsistencies, and inaccuracies in a dataset. It is a crucial step in the data science pipeline as it ensures the quality and reliability of the data.
Exploratory Data Analysis (EDA): EDA is the process of analyzing and visualizing data to gain insights and understand the underlying patterns and relationships. It involves techniques such as summary statistics, data visualization, and correlation analysis.
Feature Engineering: Feature engineering is the process of creating new features or transforming existing features in a dataset to improve the performance of machine learning models. It involves techniques such as encoding categorical variables, scaling numerical variables, and creating interaction terms.
Machine Learning Algorithms: Machine learning algorithms are mathematical models that learn patterns and relationships from data to make predictions or decisions. Some important machine learning algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines, and neural networks.
Model Evaluation and Validation: Model evaluation and validation involve assessing the performance of machine learning models on unseen data. It includes techniques such as cross-validation, confusion matrix, precision, recall, F1 score, and ROC curve analysis.
Feature Selection: Feature selection is the process of selecting the most relevant features from a dataset to improve model performance and reduce overfitting. It involves techniques such as correlation analysis, backward elimination, forward selection, and regularization methods.
Dimensionality Reduction: Dimensionality reduction techniques are used to reduce the number of features in a dataset while preserving the most important information. Principal Component Analysis (PCA) and t-SNE (t-Distributed Stochastic Neighbor Embedding) are common dimensionality reduction techniques.
Model Optimization: Model optimization involves fine-tuning the parameters and hyperparameters of machine learning models to achieve the best performance. Techniques such as grid search, random search, and Bayesian optimization are used for model optimization.
Data Visualization: Data visualization is the graphical representation of data to communicate insights and patterns effectively. It involves using charts, graphs, and plots to present data in a visually appealing and understandable manner.
Big Data Analytics: Big data analytics refers to the process of analyzing large and complex datasets that cannot be processed using traditional data processing techniques. It involves technologies such as Hadoop, Spark, and distributed computing to extract insights from massive amounts of data.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA