- 发布于
大型语言模型是如何工作的?
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
下图说明了LLM的核心架构。
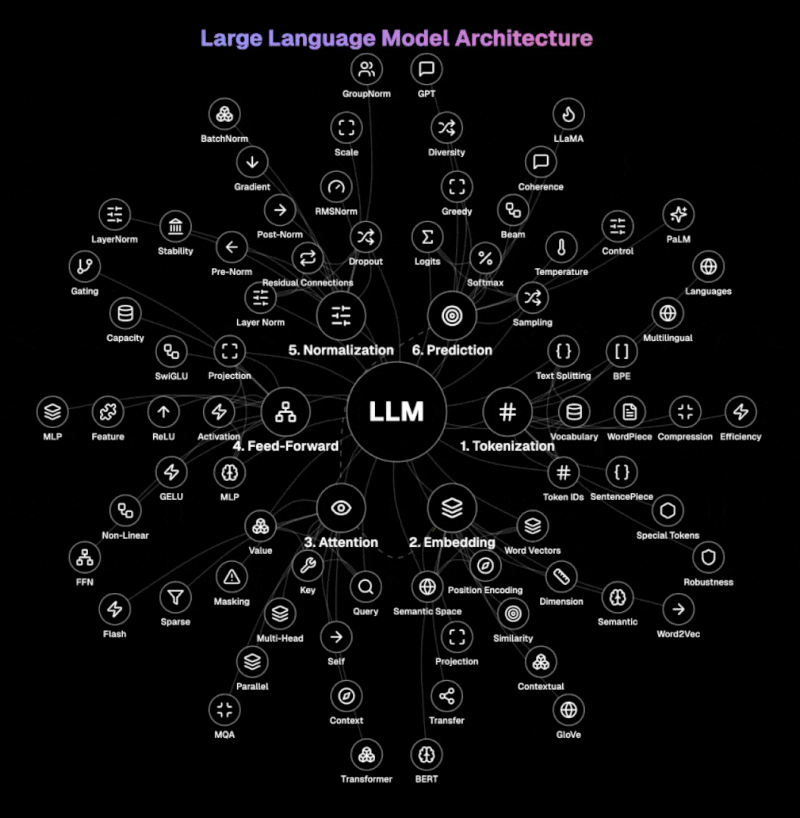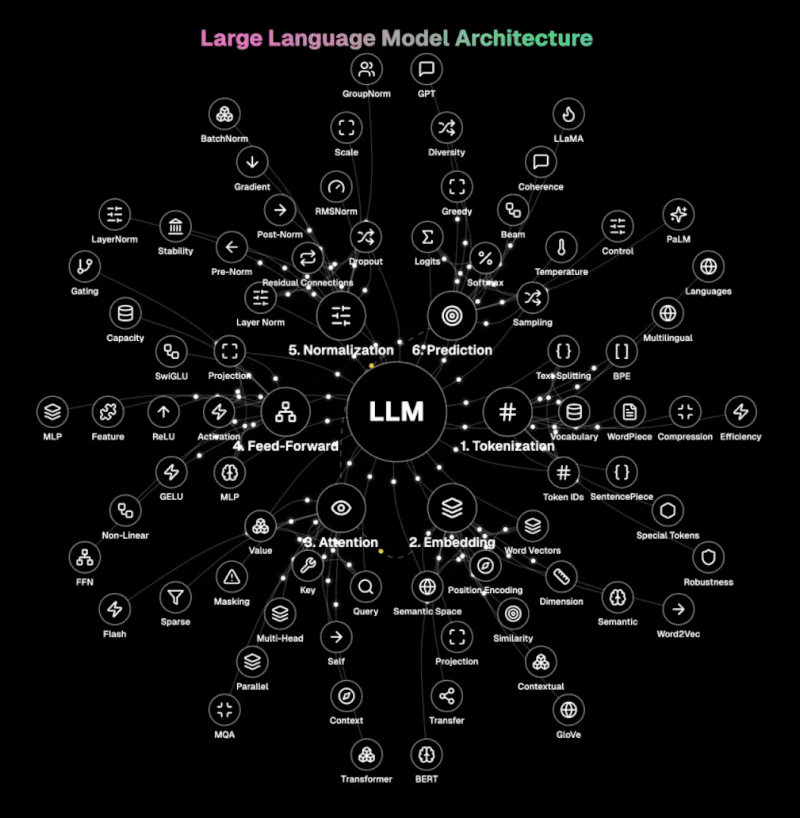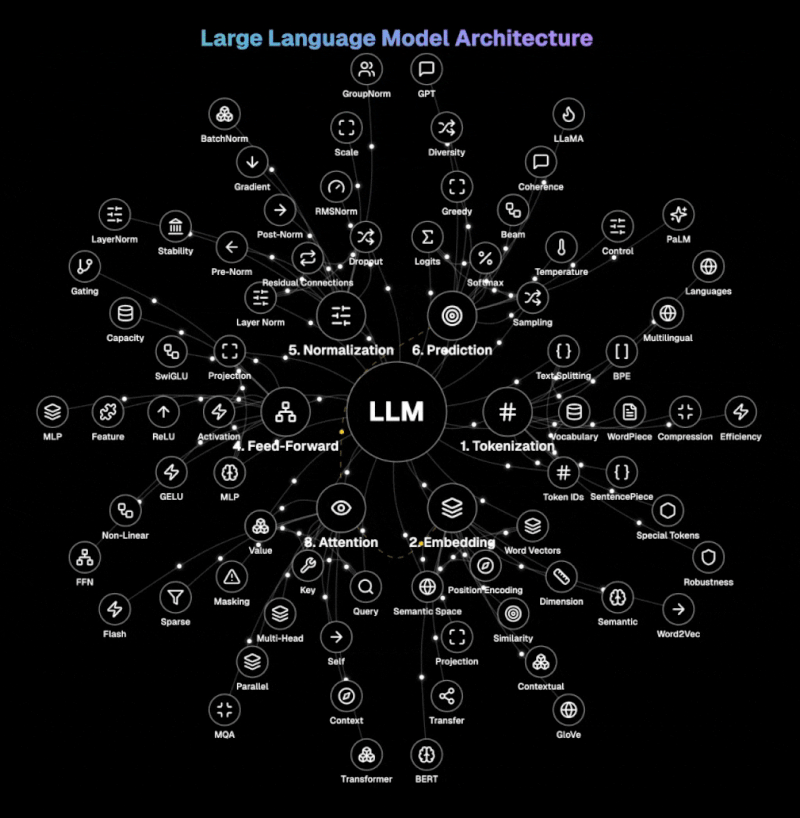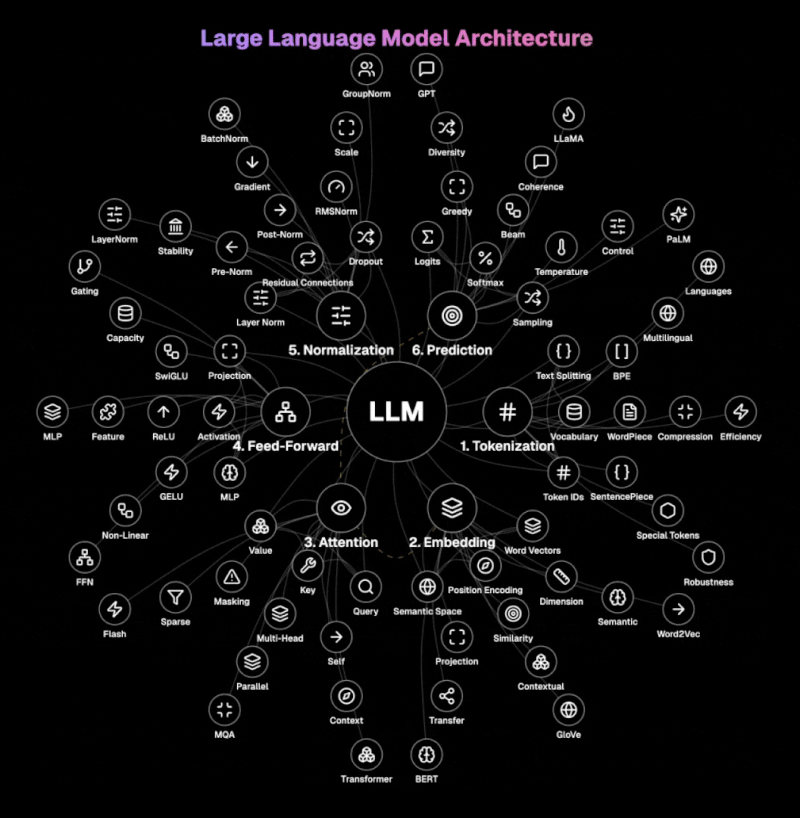
步骤 1:分词 LLM 将文本分解为可管理的单位,称为令牌。它使用 BPE、WordPiece 或 SentencePiece 等技术处理单词、子词或字符。这一过程将自然语言转换为令牌 ID,模型可以处理这些 ID,其中特殊令牌标记文本中的开始、结束或特殊功能。词汇大小和令牌压缩技术对于高效处理至关重要。
步骤 2:嵌入 该层将离散的令牌 ID 转换为高维语义空间中的丰富向量表示。它将单词向量与位置编码相结合,以保留序列信息。嵌入矩阵捕获单词之间的语义关系,允许相似的概念在向量空间中相邻。
步骤 3:注意力 现代 LLM 的核心,注意力决定了在生成每个输出令牌时要关注输入的哪些部分。使用查询、键和值向量,它计算序列中所有令牌之间的相关性得分。多头注意力并行处理信息,跨不同表示子空间捕获各种关系。自注意力允许模型在处理每个令牌时考虑整个上下文。
步骤 4:前馈 该组件通过多层感知器(MLP)独立地转换每个令牌的表示。它应用非线性激活函数,如 GELU 或 ReLU,以引入捕获数据中微妙模式的复杂性。前馈网络增加了模型表示复杂函数和关系的能力。它单独处理令牌表示,补充注意力机制的上下文处理。
步骤 5:归一化 层归一化标准化特征的输入,而残差连接允许信息直接通过网络流动。预归一化和后归一化架构提供了不同的稳定性-性能权衡。Dropout 通过在训练期间随机停用神经元来防止过拟合,迫使模型开发冗余表示。
步骤 6:预测 最后一步将处理后的表示转换为词汇表上的概率。它为每个可能的下一个令牌生成 logits(原始分数),然后使用 softmax 函数将其转换为概率。温度采样控制生成中的随机性,较低的温度会产生更确定的输出。解码策略,如贪婪、束搜索或核采样,决定了模型在生成过程中如何选择令牌。
LLM 与传统语言处理系统不同的原因是它们的自回归性质。这创建了一个一步一步的生成过程,而不是一次性产生整个响应。
在您看来:哪个架构组件会导致 LLM 中的幻觉?
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA