- 发布于
Llama-4 没有让我失望!
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
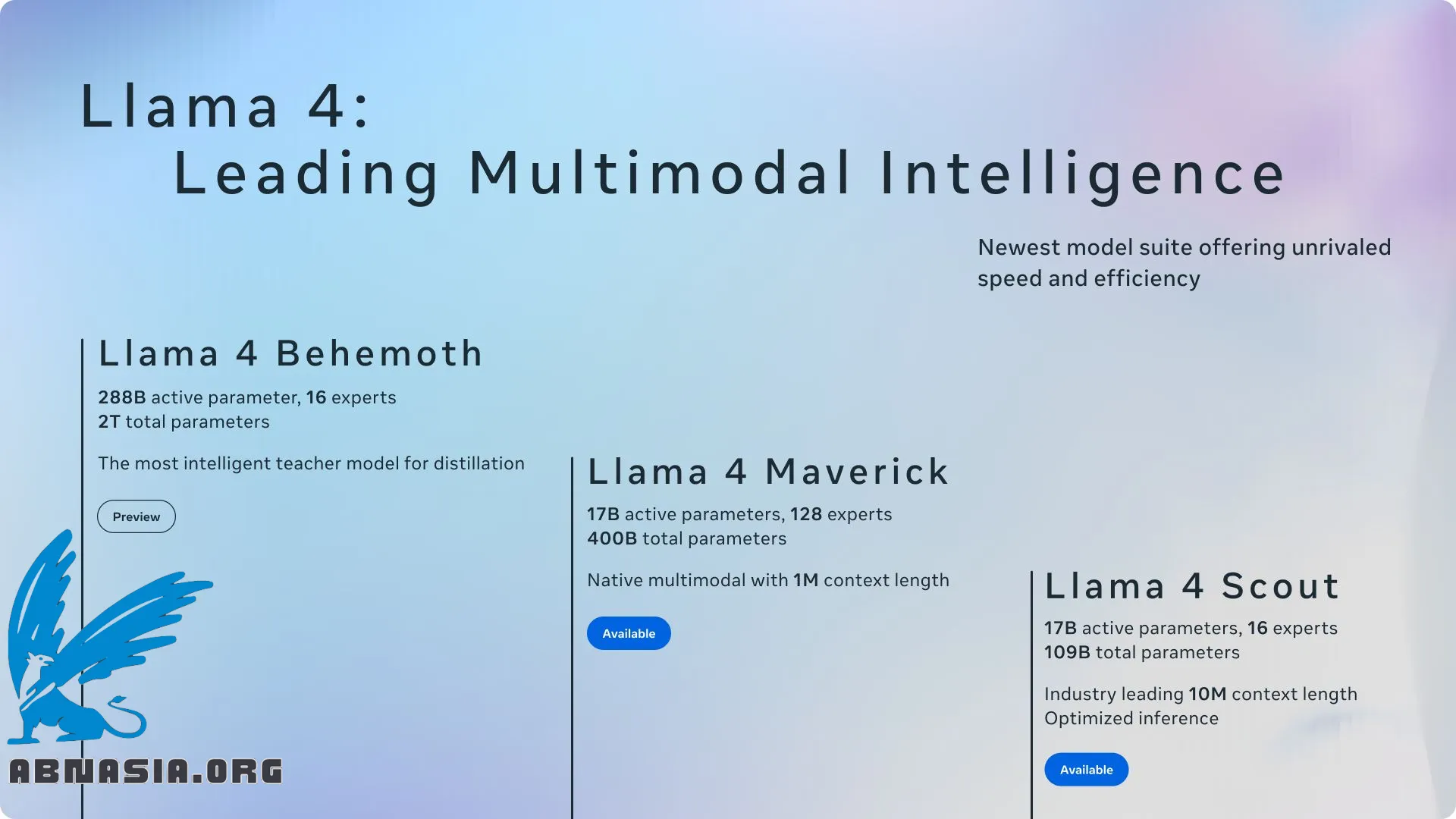
- 部署的便捷性现在比开源软件(OSS)的体积更重要。强调Llama 4 Scout可以在单个H100上运行,而Llama-3-401B虽然强大,但最终采用率较低。混合专家是OSS策略的良好方向。
- 一种新的技术称为MetaP,以智能的方式调优训练超参数。没有太多细节,但我打赌它与Meta的开源框架Ax中的贝叶斯优化类似,Ax执行具有有限试验预算的自适应实验(如A/B测试)。
- 训练后的策略是降低SFT/DPO的权重,提高RL的权重,因为SFT会过度约束模型并减少探索。
- 早期的模型检查点可以作为其后续自我的评论者。例如,模型过滤掉简单的提示,以便为下一个迭代做准备,并且在训练过程中不断改进过滤。
- Llama 4 Behemoth使用FP8、32K个GPU和30T令牌进行训练。它必须剪枝95%的SFT数据,而较小的模型只需剪枝50%。基本上,训练数据对于大型模型来说太容易了。
- 启用10M上下文的技巧似乎相当简单:(1)从每个其他注意力层中删除位置嵌入。这来自一篇引入NoPE(无位置嵌入)的论文,聪明的名字; (2)根据上下文大小调整softmax注意力。
- Grok现在是LLM社会偏见的SOTA标准!引用:“Llama 4的性能明显优于Llama 3,并且与Grok相当”在政治倾向和拒绝回答方面。
- 恭喜团队又一次发布了优秀的成果!
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA