- 发布于
数据科学家最需要了解的机器学习算法
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
这并不适合所有人。
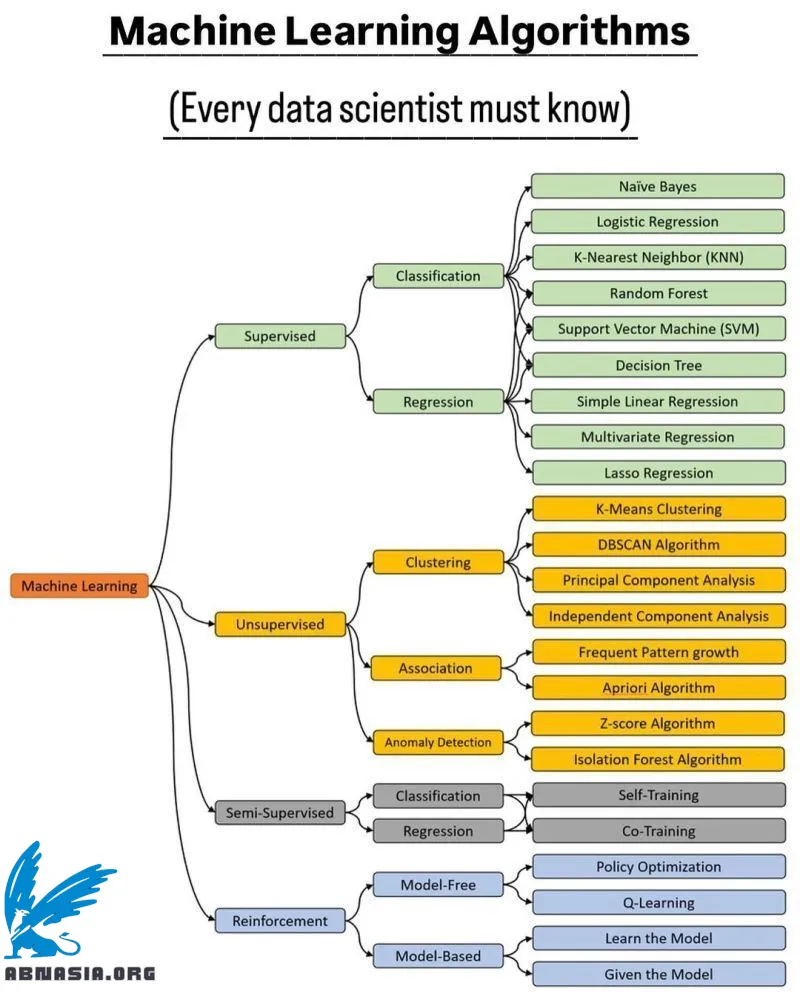
机器学习支撑着我们周围的许多事物——从推荐系统到自动驾驶汽车!
然而,了解不同类型的算法可能会很棘手。
这是对四大主要类别的快速指南:监督学习、无监督学习、半监督学习和强化学习。
- 监督学习
在监督学习中,模型从已经有答案的示例(标记数据)中学习。目标是让模型在给定新数据时预测正确的结果。
一些常见的监督学习算法包括:
➡️ 线性回归——用于预测连续值,如房价。
➡️ 逻辑回归——用于预测类别,如垃圾邮件或非垃圾邮件。
➡️ 决策树——用于逐步做出决策。
➡️ K-最近邻(KNN)——用于查找相似的数据点。
➡️ 随机森林——一组决策树,用于提高准确性。
➡️ 神经网络——深度学习的基础,模仿人脑。
- 无监督学习
在无监督学习中,模型探索没有标签的数据中的模式。它发现隐藏的结构或分组。
一些流行的无监督学习算法包括:
➡️ K-均值聚类——用于将数据分组为聚类。
➡️ 层次聚类——用于构建聚类树。
➡️ 主成分分析(PCA)——用于将数据减少到其最重要的部分。
➡️ 自编码器——用于查找数据的更简单的表示。
- 半监督学习
这是监督学习和无监督学习的混合。它使用少量标记数据和大量未标记数据来改善学习。
常见的半监督学习算法包括:
➡️ 标签传播——用于在连接的数据点之间传播标签。
➡️ 半监督支持向量机(SVM)——用于组合标记和未标记数据。
➡️ 基于图的方法——用于使用图结构改善学习。
- 强化学习
在强化学习中,模型通过试错学习。它与环境交互,接收反馈(奖励或惩罚),并学习如何行动以最大化奖励。
流行的强化学习算法包括:
➡️ Q-学习——用于学习最佳行动。
➡️ 深度Q-网络(DQN)——将Q-学习与深度学习相结合。
➡️ 策略梯度方法——用于直接学习策略。
➡️ 近端策略优化(PPO)——用于稳定和有效的学习。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA