- Veröffentlicht am
Maschinelle-Lern-Modelle: Methoden zur Modellkompression
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Warum? Weil sie jetzt viel zu groß sind.
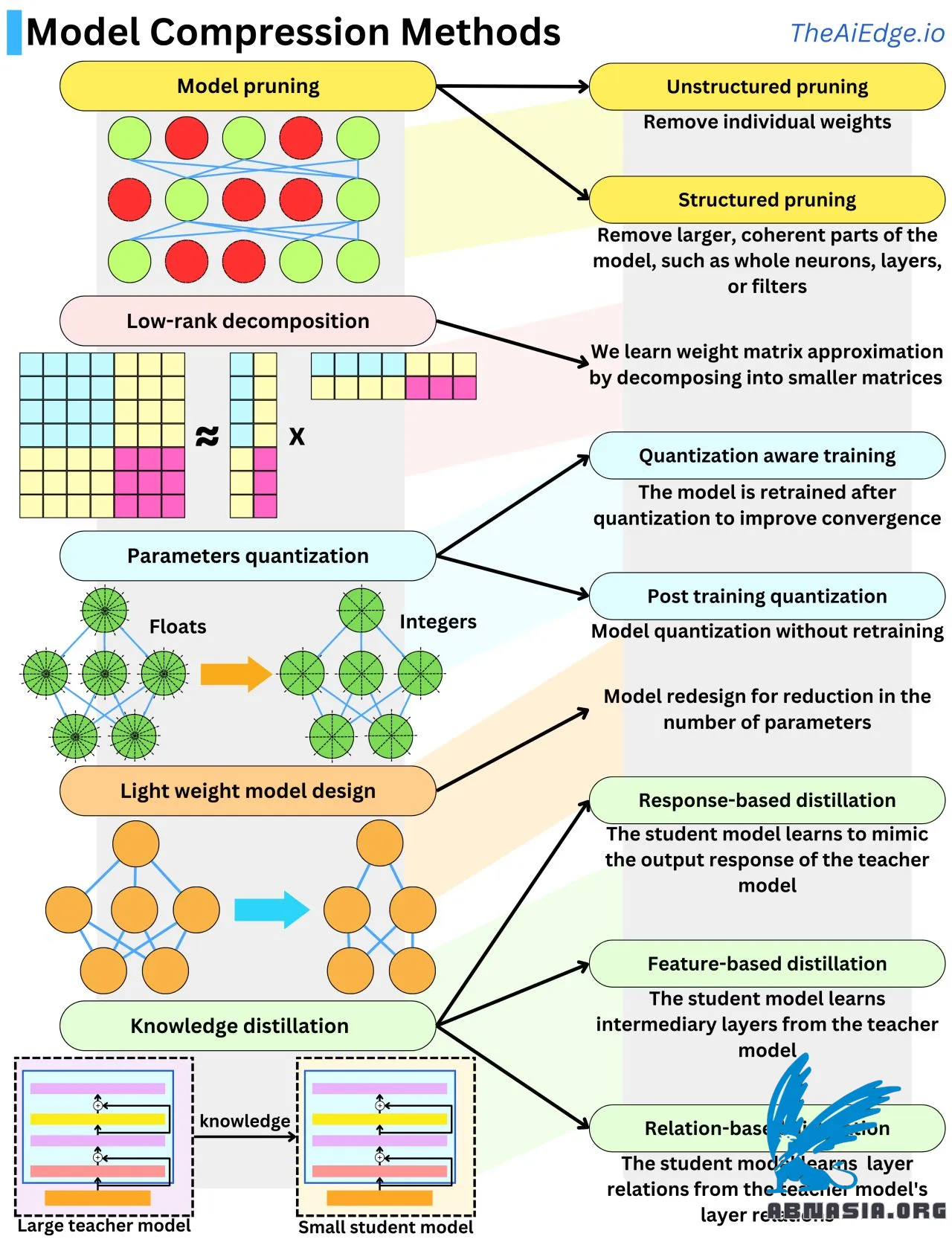
Vor nicht allzu langer Zeit erreichten die größten Machine-Learning-Modelle, mit denen die meisten Menschen zu tun hatten, lediglich ein paar GB an Speichergröße. Jetzt liegt jedes neue generative Modell, das herauskommt, zwischen 1 Milliarden und 1 Billion Parametern! Um ein Gefühl für die Größenordnung zu bekommen, entspricht ein Float-Parameter 32 Bit oder 4 Byte (oder 2 Byte mit Float16), sodass diese neuen Modelle zwischen 4 GB und 4 TB an Speicher aufwenden können, jedes auf teurer Hardware. Und während des Backpropagation-Algorithmus können diese Modelle bis zu zehnmal so viel Speicher benötigen. Aufgrund des massiven Anstiegs der Größe gibt es eine Menge Forschung, um die Modellgröße zu verringern, ohne die Leistung zu beeinträchtigen. Es gibt 5 Haupttechniken, um die Modellgröße zu komprimieren.
Modellbeschneidung dreht sich darum, unbedeutende Gewichte aus dem Netzwerk zu entfernen. Das Spiel besteht darin, zu verstehen, was "wichtig" in diesem Zusammenhang bedeutet. Ein typischer Ansatz besteht darin, die Auswirkungen auf die Verlustfunktion jedes Gewichts zu messen. Dies kann leicht gemacht werden, indem man den Gradienten und die zweite Ableitung der Verlustfunktion betrachtet. Eine andere Möglichkeit besteht darin, L1- oder L2-Regularisierung zu verwenden und die Gewichte mit geringer Amplitude zu entfernen. Das Entfernen ganzer Neuronen, Schichten oder Filter wird als "strukturierte Beschneidung" bezeichnet und ist effizienter, wenn es um die Inferenzgeschwindigkeit geht.
Modellquantisierung dreht sich darum, die Genauigkeit der Parameter zu verringern, typischerweise durch Umstellung von Float (32 Bit) auf Integer (8 Bit). Das ist eine 4-fache Modellkomprimierung. Die Quantisierung von Parametern neigt dazu, das Modell von seinem Konvergenzpunkt abzuweichen, sodass es typischerweise notwendig ist, es mit zusätzlichen Trainingsdaten zu feintunen, um die Modellleistung hoch zu halten. Wir nennen dies "Quantisierungsbewusstes Training". Wenn wir diesen letzten Schritt vermeiden, wird es als "Post-Training-Quantisierung" bezeichnet, und zusätzliche heuristische Modifikationen der Gewichte können durchgeführt werden, um die Leistung zu verbessern.
Die Low-Rank-Zerlegung basiert auf der Tatsache, dass die Gewichtsmatrizen neuronaler Netze durch Produkte von Matrizen mit niedriger Dimension approximiert werden können. Eine N x N-Matrix kann ungefähr in ein Produkt von 2 N x 1-Matrizen zerlegt werden. Das ist ein O(N^2) -> O(N) Gewinn an Speicherkomplexität!
Wissensdestillation dreht sich darum, Wissen von einem Modell auf ein anderes zu übertragen, typischerweise von einem großen Modell auf ein kleineres. Wenn das Studentenmodell lernt, ähnliche Ausgabenantworten zu produzieren, wird dies als Antwort-basierte Destillation bezeichnet. Wenn das Studentenmodell lernt, ähnliche Zwischenlagen zu reproduzieren, wird es als Merkmals-basierte Destillation bezeichnet. Wenn das Studentenmodell lernt, die Interaktion zwischen den Lagen zu reproduzieren, wird es als Beziehungs-basierte Destillation bezeichnet.
Leichtgewichtige Modellgestaltung dreht sich darum, Wissen aus empirischen Ergebnissen zu verwenden, um effizientere Architekturen zu entwerfen. Das ist wahrscheinlich eine der am häufigsten verwendeten Methoden in der LLM-Forschung.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA