- Veröffentlicht am
Tolles neues Modell aus China: Kimi k1.5: Skalierung von Reinforcement Learning mit LLMs
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
🚀 Vorstellung von Kimi k1.5 --- ein o1-Niveau-Multi-Modal-Modell
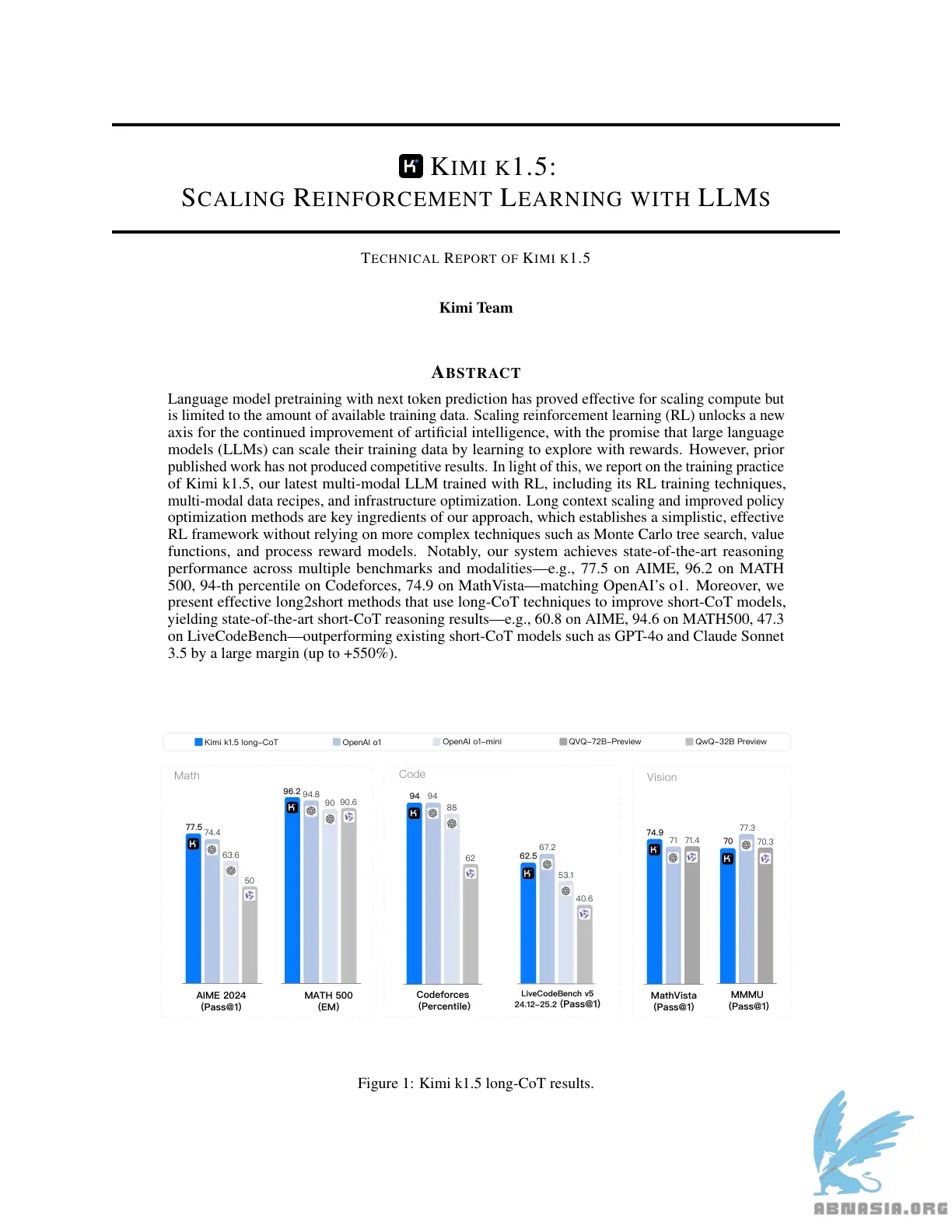

Kurz-CoT-Leistung von Sota, übertrifft GPT-4o und Claude Sonnet 3.5 auf 📐AIME, 📐MATH-500, 💻 LiveCodeBench um einen großen Betrag (bis zu +550%)
Lang-CoT-Leistung entspricht o1 über mehrere Modalitäten (👀MathVista, 📐AIME, 💻Codeforces usw)
Die Vorbereitung von Sprachmodellen mit der Vorhersage des nächsten Tokens hat sich als effektiv für die Skalierung von Rechenleistung erwiesen, ist jedoch auf die verfügbare Trainingsdatenmenge begrenzt. Die Skalierung des Reinforcement Learning (RL) schaltet einen neuen Achsen für die weitere Verbesserung der künstlichen Intelligenz frei, mit dem Versprechen, dass große Sprachmodelle (LLMs) ihre Trainingsdaten durch das Lernen mit Belohnungen skalieren können. Allerdings haben vorherige Veröffentlichungen keine wettbewerbsfähigen Ergebnisse erbracht. Vor diesem Hintergrund berichten wir über die Trainingspraxis von Kimi k1.5, unserem neuesten multi-modalen LLM, der mit RL trainiert wurde, einschließlich seiner RL-Trainingsmethoden, multi-modalen Datenrezepten und Infrastrukturoptimierung. Langkontext-Skalierung und verbesserte Richtlinienoptimierungsmethoden sind wichtige Bestandteile unseres Ansatzes, der einen einfachen, effektiven RL-Rahmen ohne die Verwendung komplexerer Techniken wie Monte-Carlo-BaumSuche, Wertfunktionen und Prozessbelohnungsmodellen bietet. Bemerkenswerterweise erreicht unser System eine Spitzenleistung bei der Argumentation über mehrere Benchmarks und Modalitäten - z.B. 77,5 auf AIME, 96,2 auf MATH 500, 94. Percentil auf Codeforces, 74,9 auf MathVista - und entspricht OpenAI's o1. Darüber hinaus präsentieren wir effektive Lang2Kurz-Methoden, die Lang-CoT-Techniken verwenden, um Kurz-CoT-Modelle zu verbessern und Spitzenleistungen bei der Kurz-CoT-Argumentation erzielen - z.B. 60,8 auf AIME, 94,6 auf MATH500, 47,3 auf LiveCodeBench - und übertrumpfen bestehende Kurz-CoT-Modelle wie GPT-4o und Claude Sonnet 3.5 um einen großen Betrag (bis zu +550%).
Es gibt einige wichtige Bestandteile bei der Konstruktion und dem Training von k1.5.
Langkontext-Skalierung. Wir skalieren das Kontextfenster von RL auf 128k und beobachten eine kontinuierliche Verbesserung der Leistung bei zunehmender Kontextlänge. Eine wichtige Idee hinter unserem Ansatz ist die Verwendung von partiellen Rollouts, um die Trainings-effizienz zu verbessern - d.h. das Sampling neuer Trajektoren durch Wiederverwendung eines großen Teils vorheriger Trajektoren, um die Kosten für die Neugenerierung neuer Trajektoren von Grund auf zu vermeiden. Unsere Beobachtung identifiziert die Kontextlänge als eine wichtige Dimension für die weitere Skalierung von RL mit LLMs.
Verbesserte Richtlinienoptimierung. Wir leiten eine Formulierung von RL mit Lang-CoT ab und verwenden eine Variante des Online-Mirror-Abstiegs für eine robuste Richtlinienoptimierung. Dieser Algorithmus wird weiter verbessert durch unsere effektive Sampling-Strategie, Längenstrafe und Optimierung des Datenrezepts.
Einfacher Rahmen. Langkontext-Skalierung, kombiniert mit den verbesserten Richtlinienoptimierungsmethoden, etabliert einen einfachen RL-Rahmen für das Lernen mit LLMs. Da wir die Kontextlänge skalieren können, zeigen die gelernten CoTs die Eigenschaften von Planung, Reflexion und Korrektur. Eine erhöhte Kontextlänge hat die Wirkung, die Anzahl der Suchschritte zu erhöhen. Als Ergebnis zeigen wir, dass eine starke Leistung ohne die Verwendung komplexerer Techniken wie Monte-Carlo-BaumSuche, Wertfunktionen und Prozessbelohnungsmodellen erzielt werden kann.
Multimodalitäten. Unser Modell wird gemeinsam auf Text- und Bildaten trainiert, was die Fähigkeit besitzt, gemeinsam über die beiden Modalitäten zu argumentieren.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA