- Veröffentlicht am
Warum GraphRAG eines der besten RAG-Systeme ist
- Autoren

- Name
- AbnAsia.org
- @steven_n_t
Graph-Datenbanken sollten die bessere Wahl für Retrieval Augmented Generation (RAG) sein!
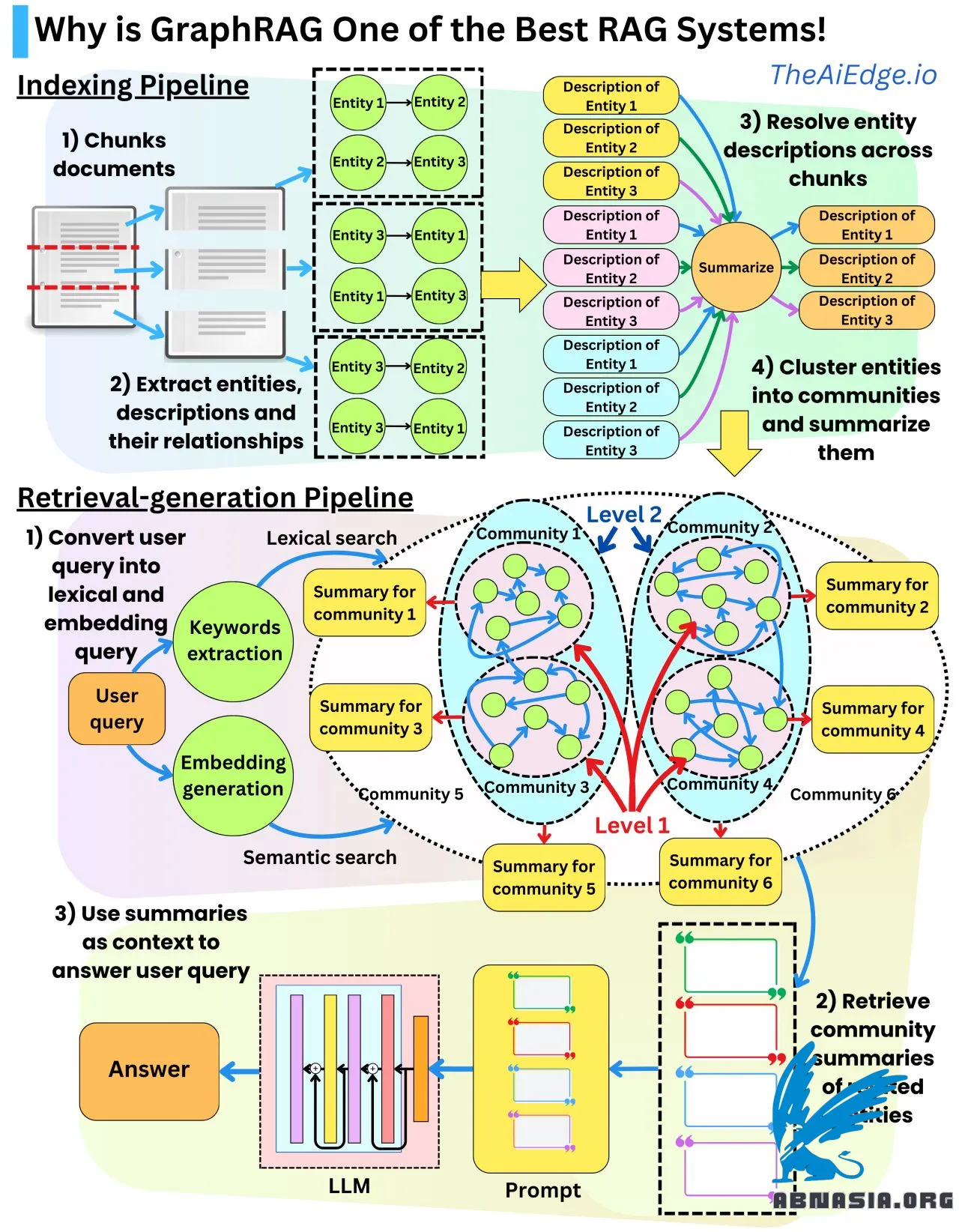
RAG-Systeme sind normalerweise ziemlich schlecht darin, den richtigen Kontext abzurufen! Die abgerufene Information ist sehr lokal auf die ursprünglichen Dokumente beschränkt, und es kann schwierig sein, die Dokumente zu erhalten, die tatsächlich mit der Benutzeranfrage zusammenhängen. Genau hier kann Microsoft GraphRAG eine Lösung bieten!
Es gibt zwei wichtige Teile. Zuerst werden wir Zusammenfassungen der verschiedenen Dokumente in unterschiedlichen Skalen erstellen. Auf diese Weise können wir insgesamt verstehen, welche globalen Informationen in den vollständigen Dokumenten enthalten sind, sowie die lokalen Informationen, die in kleineren Textabschnitten enthalten sind. Zweitens werden wir die textuelle Information in ihre grafische Form reduzieren. Die Annahme ist, dass die in dem Text enthaltene Information als eine Menge von Knoten und Kanten dargestellt werden kann. Dies ermöglicht die Darstellung der vollständigen Information, die im Text enthalten ist, als Wissensbasis, die in einer Graph-Datenbank gespeichert werden kann.
Die Daten-Indexierungspipeline ist wie folgt:
- Wir teilen die ursprünglichen Dokumente in Subtexte auf.
- Wir extrahieren die Entitäten, ihre Beziehungen und ihre Beschreibungen in einem strukturierten Format mithilfe eines LLM.
- Wir lösen die doppelten Entitäten und Beziehungen, die wir in den verschiedenen Textabschnitten finden können. Wir können die verschiedenen Beschreibungen in umfassendere zusammenfassen.
- Wir erstellen die grafische Darstellung der Entitäten und ihrer Beziehungen.
- Aus dem Graphen gruppieren wir die verschiedenen Entitäten in Gemeinschaften in einer hierarchischen Weise mithilfe des Leiden-Algorithmus. Jede Entität gehört zu mehreren Clustern, abhängig von der Skala der Cluster.
- Für jede Gemeinschaft fassen wir sie zusammen, indem wir die Entitäts- und Beziehungsbeschreibungen verwenden. Wir haben mehrere Zusammenfassungen für jede Entität, die die verschiedenen Skalen der Gemeinschaften darstellen.
Zur Abrufzeit können wir die Benutzeranfrage konvertieren, indem wir Schlüsselwörter für eine lexikalische Suche und eine Vektor-Darstellung für eine semantische Suche extrahieren. Aus der Suche erhalten wir Entitäten, und aus den Entitäten erhalten wir ihre zugehörigen Gemeinschaftszusammenfassungen. Diese Zusammenfassungen werden als Kontext im Prompt bei der Generierungszeit verwendet, um die Benutzeranfrage zu beantworten.
Wir verstehen Dinge erst, wenn wir sie implementieren.
Bitte beachten Sie, dass die deutsche Version von Ai unterstützt wird und daher geringfügige Fehler auftreten können.
AUTOR
Über ABN Asia: Ai Base Network (ABN), ABN Asia wurde im Jahr 2012 gegründet und ist ein Unternehmen mit akademischem Hintergrund, das von Lehrkräften und ehemaligen Studierenden aus Ungarn, den Niederlanden, Russland, Deutschland und Japan gegründet wurde. Wir teilen eine gemeinsame Leidenschaft und eine klare Vision für Technologie, die Innovation und erstklassige Qualität für unsere Kunden bringt. Unser Motto lautet: Besser. Schneller. Sicherer. In vielen Fällen: Günstiger.
Zögern Sie nicht, uns zu kontaktieren, wenn Sie IT-Dienstleistungen, digitale Beratung, Standardsoftwarelösungen benötigen oder uns Angebotsanfragen (RFPs) senden möchten. Sie können uns unter [email protected] kontaktieren. Wir sind bereit, Ihnen bei all Ihren Technologiebedürfnissen zu helfen.

© ABN ASIA