- Published on
Chatbot Ranking: Differen Tasks, different winners
- Authors

- Name
- AbnAsia.org
- @steven_n_t
It is not well known that Chatbot Arena publishes category-based ratings for prompts like Maths, Coding or Creative Writing as well as adjustment for style.
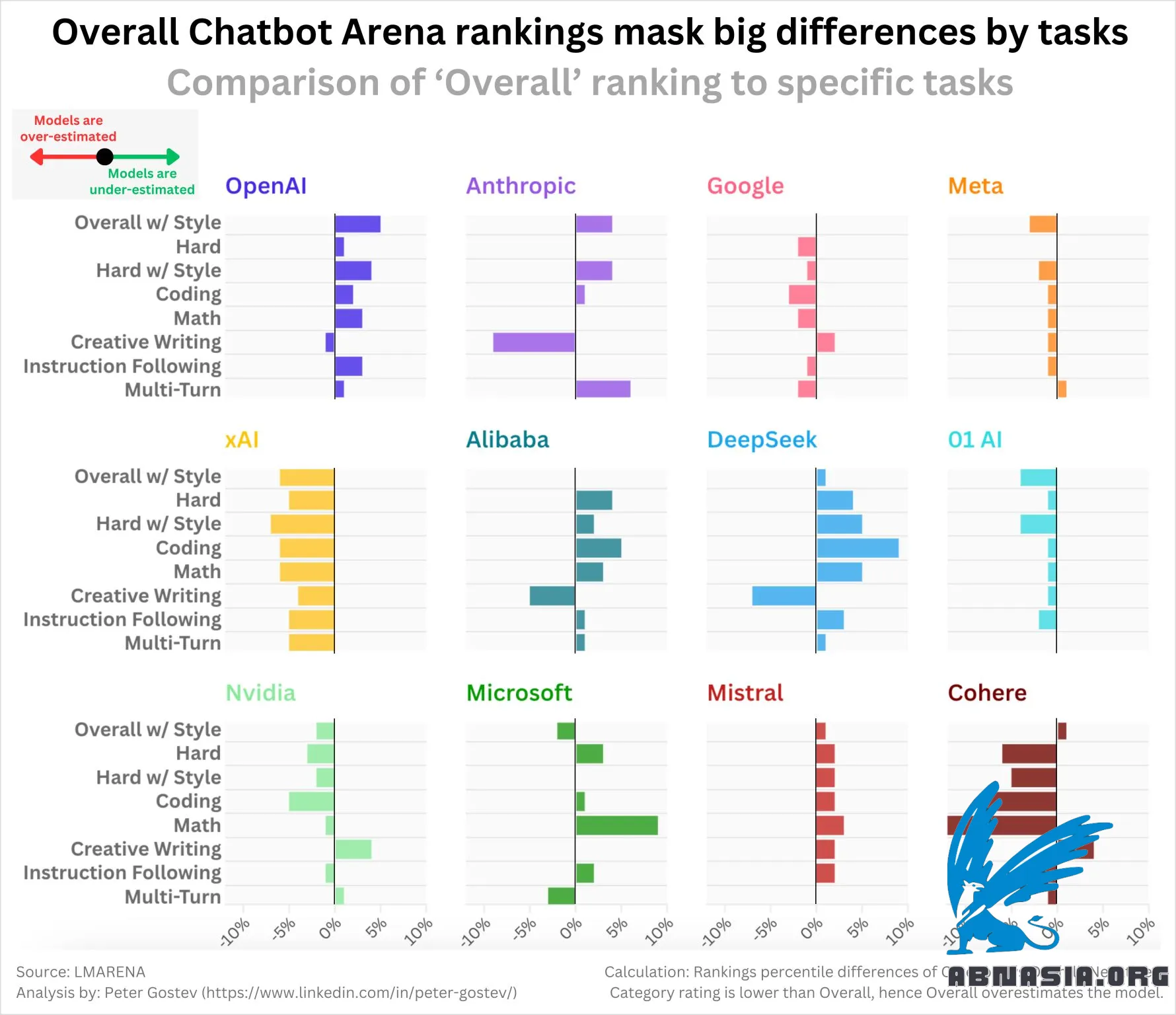
Meaning that we can see what the 'core' performance of the model for certain tasks.
I was interested in exploring whether certain labs tend to be under or over-estimated by the 'Overall' rating for various tasks. Results are honestly not quite what I expected:
OpenAI models are mostly under estimated (i.e. they are stronger if you look at individual ratings)
xAI, Google, Meta, 01 (lab, not model), Cohere, Nvidia are all over-estimated
DeepSeek, Mistral, Alibaba (Qwen models) are under-estimated
Anthropic more mixed - over-estimation for creative writing is kind of interesting
As a tip, if you want to look at the best models, I would suggest looking at 'Hard with Style Control' - where Sonnet 3.6, o1-preview, and Google-Exp-1121 are joint first - it matches my intuition about what the best models are much better.
Author
Ai Base Network (ABN), ABN ASIA was founded by people with deep roots in academia, with work experience in the US, Holland, Hungary, Japan, South Korea, Singapore, and Vietnam. ABN Asia is where academia and technology meet opportunity. With our cutting-edge solutions and competent software development services, we're helping businesses level up and take on the global scene. Our commitment: Faster. Better. More reliable. In most cases: Cheaper as well.
Feel free to reach out to us whenever you require IT services, digital consulting, off-the-shelf software solutions, or if you'd like to send us requests for proposals (RFPs). You can contact us at [email protected]. We're ready to assist you with all your technology needs.

© ABN ASIA