- Publié le
4 stratégies d'entraînement multi-GPU expliquées de manière visuelle.
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Par défaut, les modèles d'apprentissage profond n'utilisent qu'une seule carte graphique pour l'entraînement, même si plusieurs cartes graphiques sont disponibles. Voici une astuce.
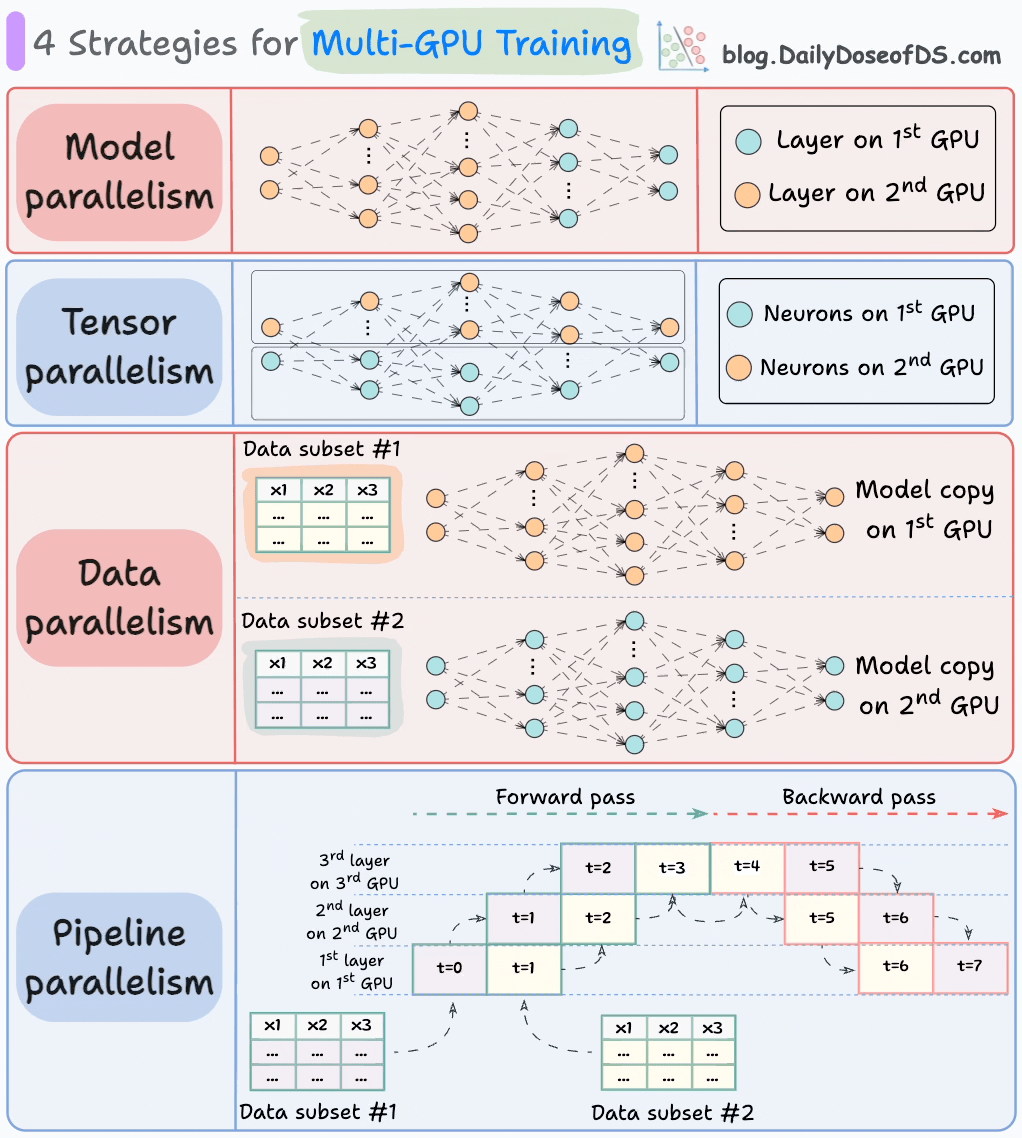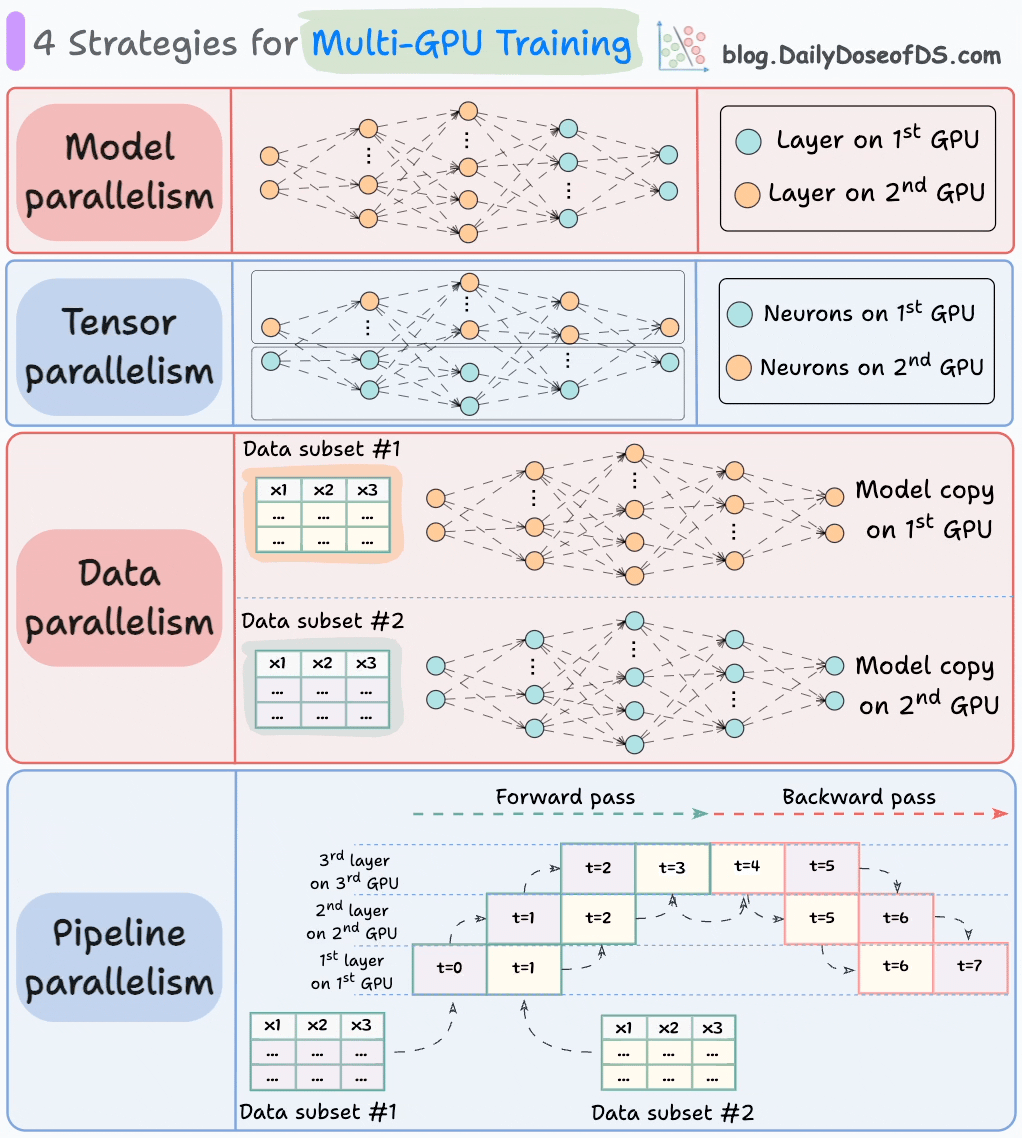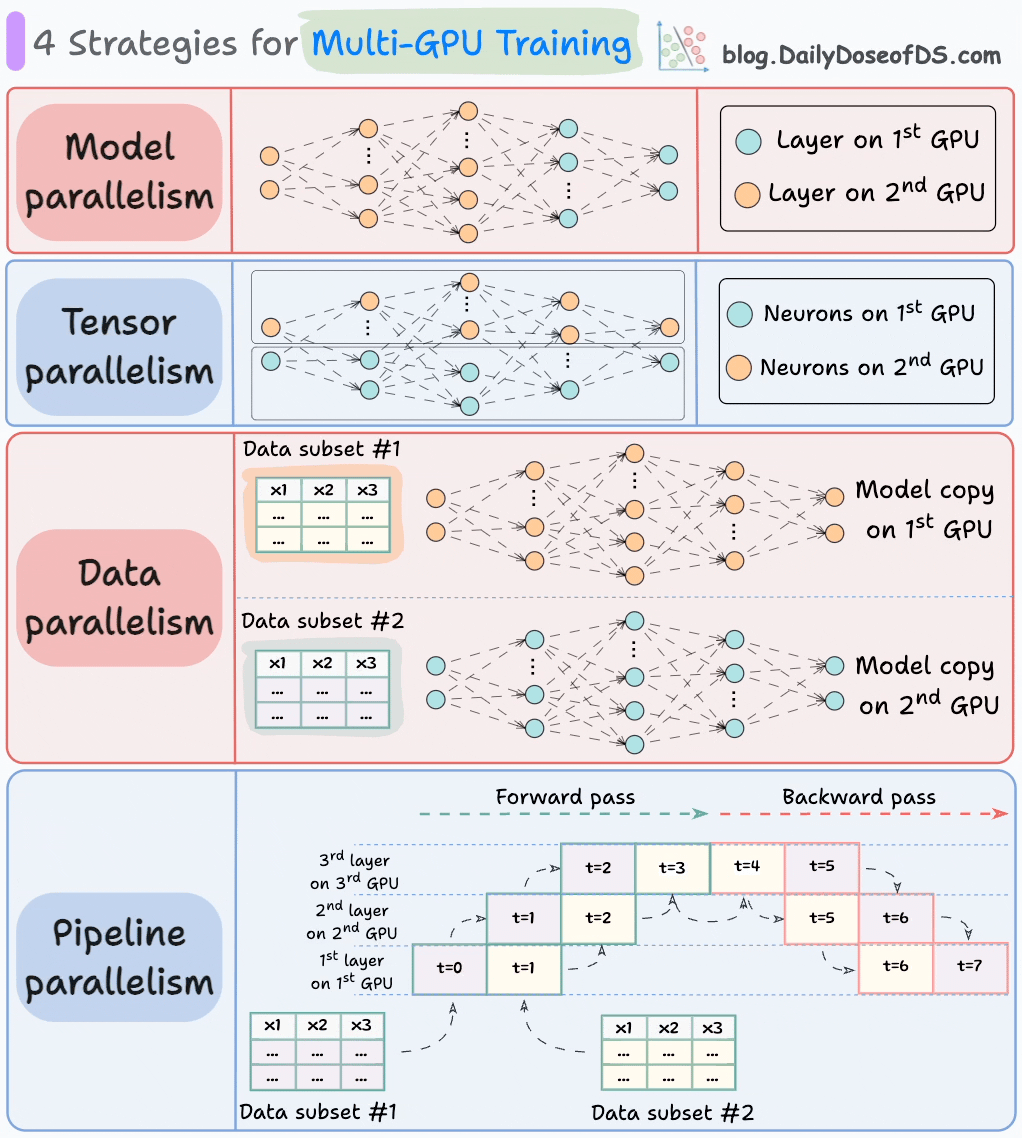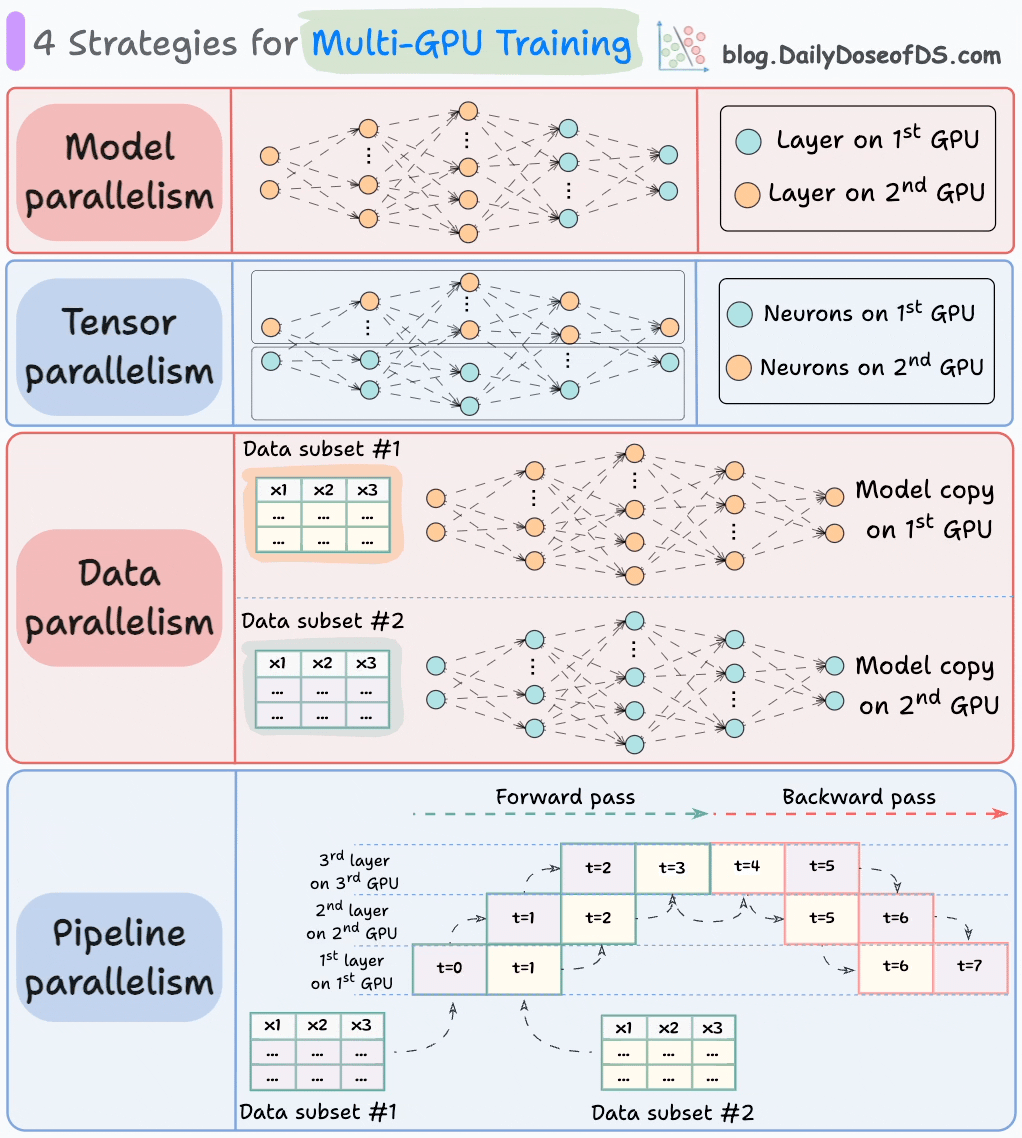
Une façon idéale de procéder (surtout dans les environnements de données massives) est de répartir la charge de travail d'entraînement sur plusieurs GPU.
Le graphique ci-dessous illustre quatre stratégies courantes pour l'entraînement multi-GPU :
- Parallélisme de modèle
- Différentes parties (ou couches) du modèle sont placées sur différents GPU.
- Utile pour les modèles énormes qui ne tiennent pas sur un seul GPU.
- Cependant, le parallélisme de modèle introduit également des goulets d'étranglement graves car il nécessite un flux de données entre les GPU lorsque les activations d'un GPU sont transférées vers un autre GPU.
- Parallélisme de tenseur
- Répartit et traite les opérations de tenseur individuelles sur plusieurs appareils ou processeurs.
- Il repose sur l'idée qu'une grande opération de tenseur, telle que la multiplication de matrices, peut être divisée en opérations de tenseur plus petites, et que chaque opération plus petite peut être exécutée sur un appareil ou processeur séparé.
- De telles stratégies de parallélisation sont inhérentes aux implémentations standard de PyTorch et d'autres frameworks d'apprentissage profond, mais elles deviennent beaucoup plus prononcées dans un environnement distribué.
- Parallélisme de données
- Répliquez le modèle sur tous les GPU.
- Divisez les données disponibles en lots plus petits, et chaque lot est traité par un GPU séparé.
- Les mises à jour (ou gradients) de chaque GPU sont ensuite agrégées et utilisées pour mettre à jour les paramètres du modèle sur chaque GPU.
- Parallélisme de pipeline
Ceci est souvent considéré comme une combinaison de parallélisme de données et de parallélisme de modèle.
Le problème avec le parallélisme de modèle standard est que le 1er GPU reste inactif lorsque les données sont propagées à travers les couches disponibles sur le 2ème GPU :
Le parallélisme de pipeline résout ce problème en chargeant le prochain micro-lot de données une fois que le 1er GPU a terminé les calculs sur le 1er micro-lot et transféré les activations vers les couches disponibles sur le 2ème GPU.
Le processus ressemble à ceci :
↳ Le 1er micro-lot passe à travers les couches sur le 1er GPU.
↳ Le 2ème GPU reçoit les activations sur le 1er micro-lot du 1er GPU.
↳ Pendant que le 2ème GPU passe les données à travers les couches, un autre micro-lot est chargé sur le 1er GPU.
↳ Et le processus continue.
- L'utilisation du GPU s'améliore considérablement de cette façon. C'est évident à partir de l'animation ci-dessous où plusieurs GPU sont utilisés au même horodatage (regardez t=1, t=2, t=5 et t=6).
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA