- Publié le
Ce qui compte dans les Transformers ?
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Ce qui compte dans les Transformers ? est un article intéressant qui montre qu'il est possible de supprimer la moitié des couches d'attention dans les LLM comme Llama sans réduire de manière notable les performances de modélisation.
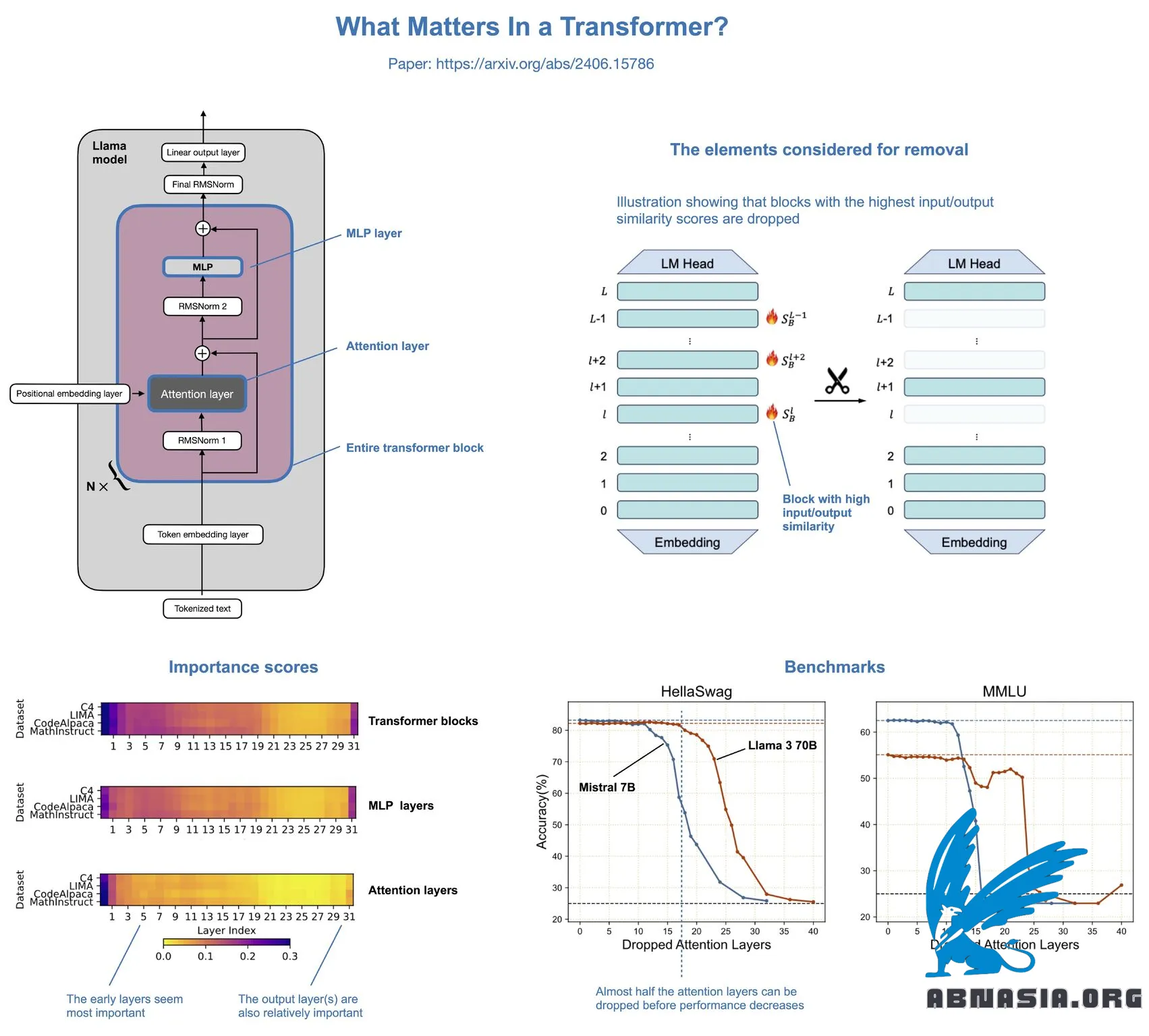
Le concept est relativement simple. Les auteurs suppriment les couches d'attention, les couches MLP ou des blocs de transformateurs entiers :
La suppression de blocs de transformateurs entiers entraîne une dégradation significative des performances.
La suppression des couches MLP entraîne une dégradation significative des performances.
La suppression des couches d'attention entraîne presque aucune dégradation des performances !
Dans Llama 2 70B, même si la moitié des couches d'attention sont supprimées (ce qui entraîne une accélération de 48 %), il n'y a qu'une diminution de 2,4 % des benchmarks du modèle. L'auteur a également récemment ajouté les résultats de Llama 3 à l'article, qui sont similaires.
Les couches d'attention n'ont pas été supprimées de manière aléatoire, mais en fonction d'un score de similarité basé sur le cosinus : si l'entrée et la sortie sont très similaires, la couche est redondante et peut être supprimée.
C'est un résultat super intrigant qui pourrait potentiellement être combiné avec diverses techniques de compression de modèle (comme la taille et la quantification) pour des effets cumulatifs.
De plus, les couches sont supprimées d'une seule traite (et non de manière itérative) et aucune (re)formation n'est requise après la suppression. Cependant, la reformation du modèle après la suppression pourrait potentiellement récupérer une partie des performances perdues.
Dans l'ensemble, une étude très simple mais très intéressante. Il semble qu'il puisse y avoir beaucoup de redondance computationnelle dans les architectures plus grandes.
Une grande réserve de cette étude, cependant, est que l'accent est mis principalement sur les benchmarks universitaires (HellaSwag, MMLU, etc.). Il n'est pas clair comment les modèles se comportent sur les benchmarks qui mesurent les performances conversationnelles.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA