- Publié le
Comment fonctionnent les grands modèles de langage ?
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Le diagramme ci-dessous illustre l'architecture de base des LLM.
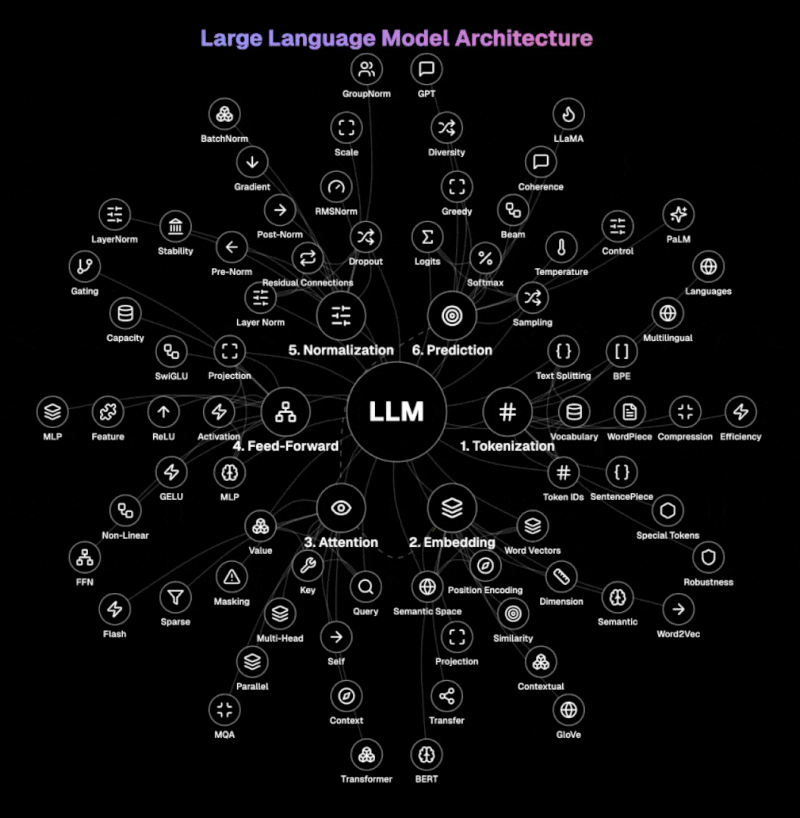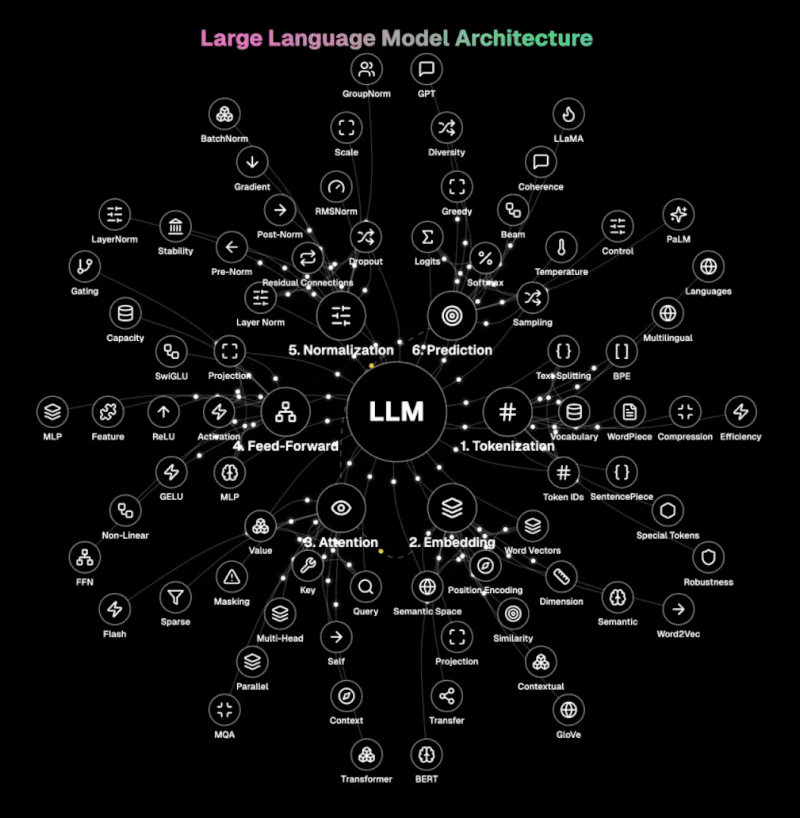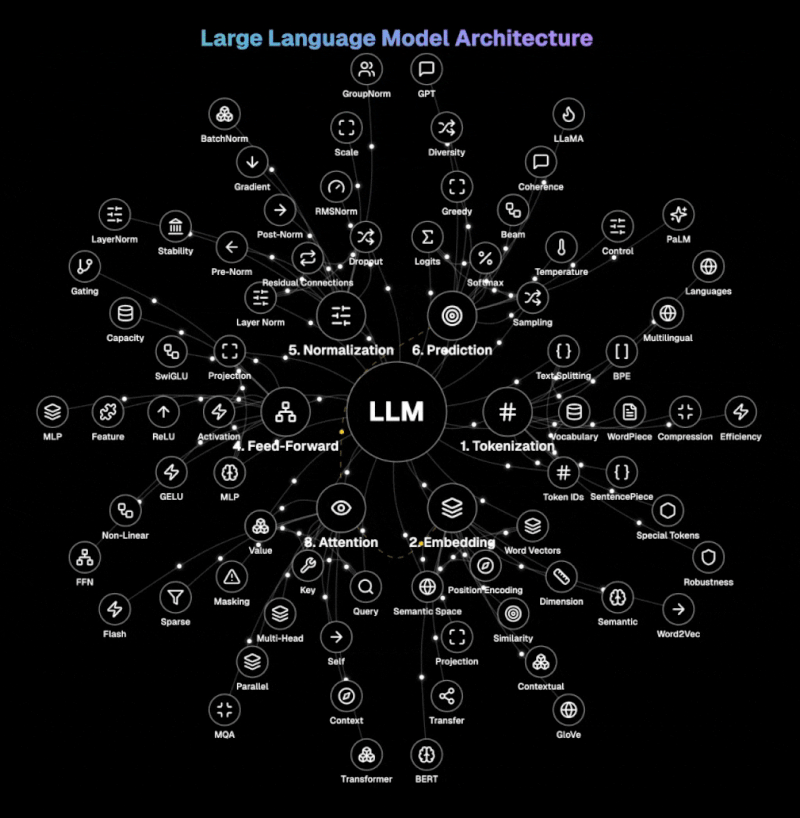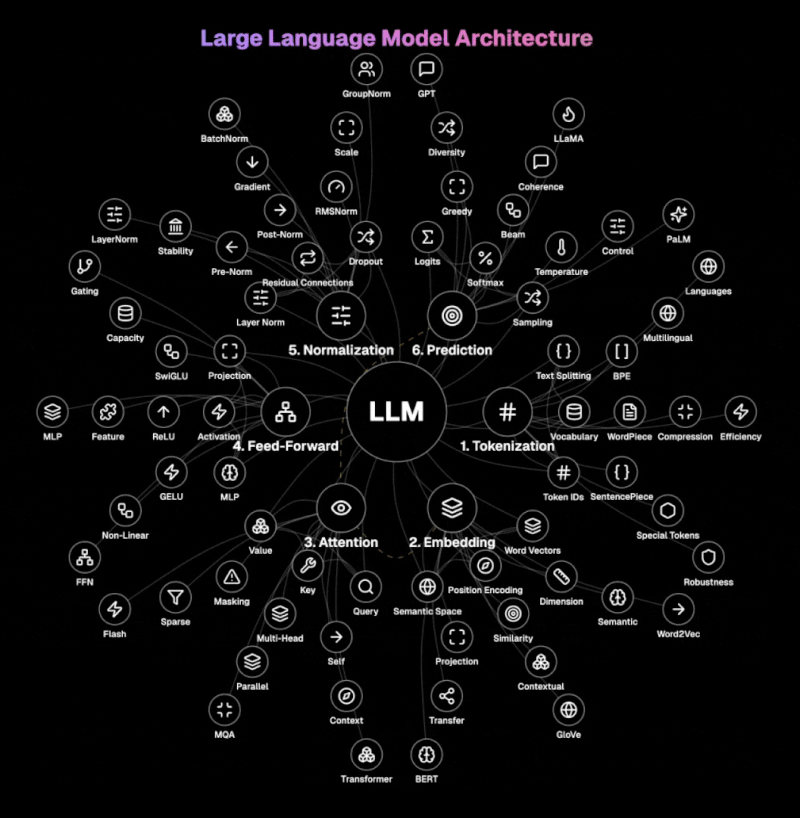
Étape 1 : Tokenisation Le LLM divise le texte en unités gérables appelées jetons. Il gère les mots, les sous-mots ou les caractères à l'aide de techniques comme BPE, WordPiece ou SentencePiece. Ce processus transforme le langage naturel en ID de jetons que le modèle peut traiter, avec des jetons spéciaux marquant le début, la fin ou des fonctions spéciales dans le texte. La taille du vocabulaire et les techniques de compression de jetons sont cruciales pour un traitement efficace.
Étape 2 : Intégration Cette couche transforme les ID de jetons discrets en représentations vectorielles riches dans un espace sémantique à haute dimension. Elle combine les vecteurs de mots avec un codage positionnel pour préserver les informations de séquence. La matrice d'intégration capture les relations sémantiques entre les mots, permettant à des concepts similaires d'exister à proximité les uns des autres dans l'espace vectoriel.
Étape 3 : Attention Au cœur des LLM modernes, l'attention détermine quelles parties de l'entrée se concentrer sur lors de la génération de chaque jeton de sortie. En utilisant des vecteurs de requête, de clé et de valeur, elle calcule les scores de pertinence entre tous les jetons de la séquence. L'attention multi-tête traite les informations en parallèle à travers différents sous-espaces de représentation, capturant ainsi diverses relations simultanément. L'auto-attention permet au modèle de considérer l'ensemble du contexte lors du traitement de chaque jeton.
Étape 4 : Feed-Forward Ce composant transforme la représentation de chaque jeton de manière indépendante à travers un perceptron multi-couche (MLP). Il applique des fonctions d'activation non linéaires comme GELU ou ReLU pour introduire de la complexité qui capture des modèles subtils dans les données. Le réseau feed-forward augmente la capacité du modèle à représenter des fonctions et des relations complexes. Il traite les représentations de jetons individuellement, complétant ainsi le traitement contextuel du mécanisme d'attention.
Étape 5 : Normalisation La normalisation de couche standardise les entrées à travers les fonctionnalités, tandis que les connexions résiduelles permettent à l'information de s'écouler directement à travers le réseau. Les architectures pre-norm et post-norm offrent différents compromis entre stabilité et performances. Le dropout empêche le surapprentissage en désactivant aléatoirement les neurones pendant l'entraînement, forçant ainsi le modèle à développer des représentations redondantes.
Étape 6 : Prédiction La dernière étape transforme les représentations traitées en probabilités sur le vocabulaire. Elle génère des logits (scores bruts) pour chaque jeton possible suivant, qui sont convertis en probabilités à l'aide de la fonction softmax. L'échantillonnage de température contrôle l'aléatoire dans la génération, avec des températures plus basses produisant des sorties plus déterministes. Les stratégies de décodage comme la recherche gloutonne, la recherche en faisceau ou l'échantillonnage de noyau déterminent la façon dont le modèle sélectionne les jetons pendant la génération.
Ce qui rend les LLM différents des systèmes de traitement du langage traditionnels, c'est leur nature autorégressive. Cela crée un processus de génération étape par étape plutôt que de produire des réponses entières à la fois.
À votre avis : Quel composant architectural est à l'origine des hallucinations dans les LLM ?
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA