- Publié le
Pourquoi GraphRAG est l'un des meilleurs systèmes RAG
- Auteurs

- Nom
- AbnAsia.org
- @steven_n_t
Les bases de données graphiques devraient être le meilleur choix pour la génération augmentée de récupération (RAG) !
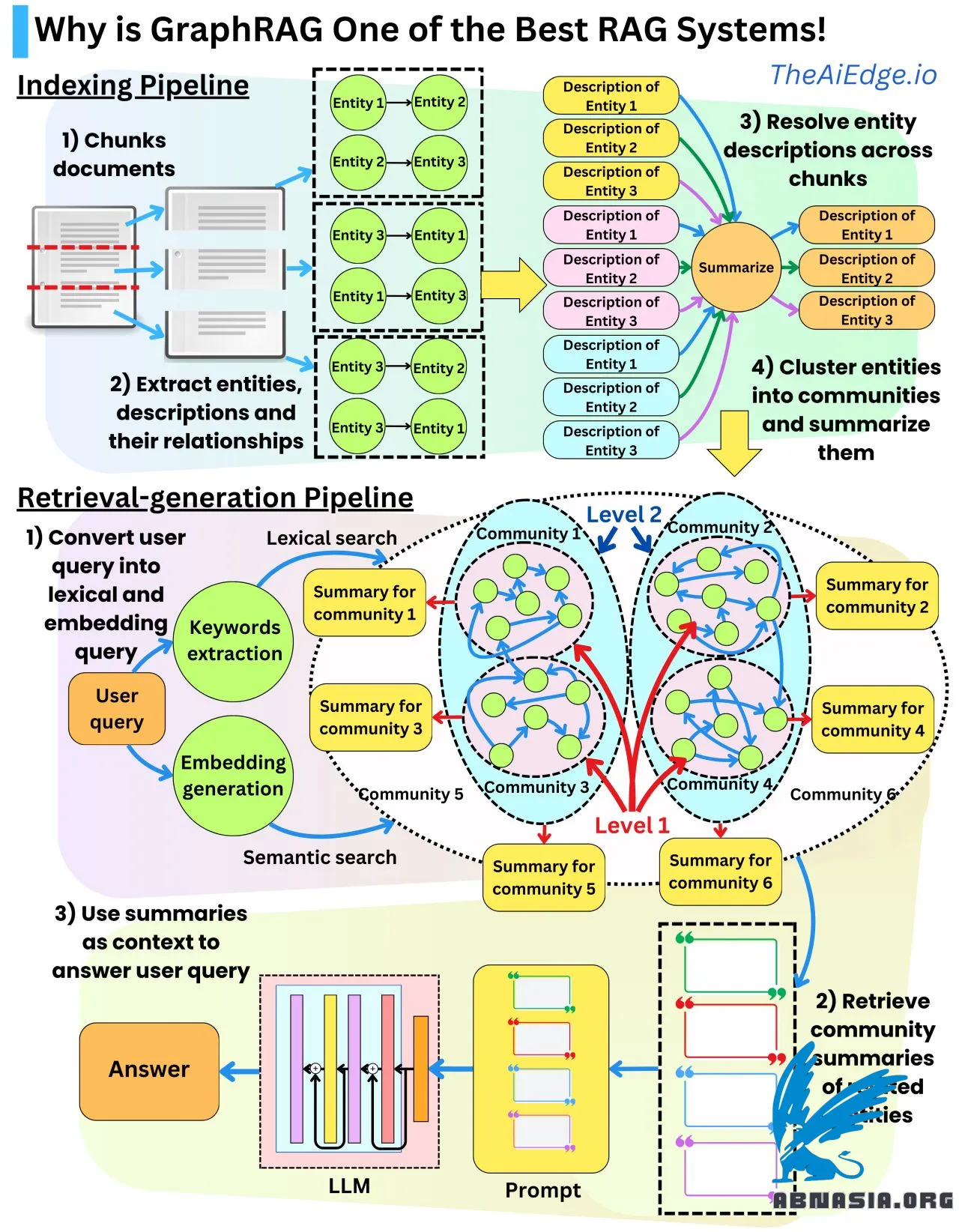
Les systèmes RAG sont généralement assez mauvais pour récupérer le bon contexte ! Les informations récupérées sont très locales par rapport aux documents d'origine, et il peut être difficile d'obtenir les documents qui sont réellement liés à la requête de l'utilisateur. C'est là que Microsoft GraphRAG peut fournir une solution !
Il y a deux éléments importants. Premièrement, nous allons créer des résumés des différents documents à différentes échelles. De cette façon, nous allons pouvoir comprendre, globalement, quelles informations globales sont contenues dans les documents complets, ainsi que les informations locales contenues dans des morceaux de texte plus petits. Deuxièmement, nous allons réduire les informations textuelles à leur forme graphique. L'hypothèse est que les informations contenues dans le texte peuvent être représentées sous forme de nœuds et de liens. Cela permet de représenter l'ensemble des informations contenues dans le texte sous forme de base de connaissances qui peut être stockée dans une base de données graphique.
Le pipeline d'indexation des données est le suivant :
- Nous divisons les documents d'origine en sous-textes.
- Nous extrayons les entités, leurs relations et leurs descriptions dans un format structuré en utilisant un LLM.
- Nous résolvons les entités et les relations en double que nous pouvons trouver dans les différents morceaux de texte. Nous pouvons résumer les différentes descriptions en des descriptions plus complètes.
- Nous construisons la représentation graphique des entités et de leurs relations.
- À partir du graphique, nous regroupons les différentes entités en communautés de manière hiérarchique en utilisant l'algorithme de Leiden. Chaque entité appartient à plusieurs communautés en fonction de l'échelle des communautés.
- Pour chaque communauté, nous résumons en utilisant les descriptions des entités et des relations. Nous avons plusieurs résumés pour chaque entité représentant les différentes échelles des communautés.
Au moment de la récupération, nous pouvons convertir la requête de l'utilisateur en extrayant des mots-clés pour une recherche lexicale et une représentation vectorielle pour une recherche sémantique. À partir de la recherche, nous obtenons des entités, et à partir des entités, nous obtenons les résumés des communautés liées. Ces résumés sont utilisés comme contexte dans la requête à l'heure de la génération pour répondre à la requête de l'utilisateur.
Nous ne comprenons les choses qu'une fois que nous les implémentons.
Veuillez noter que la version française est assistée par Ai, des erreurs mineures peuvent donc exister.
Auteur
Ai Base Network (ABN), ABN ASIA a été fondée par des personnes ayant des racines profondes dans le milieu académique, avec une expérience professionnelle aux États-Unis, aux Pays-Bas, en Hongrie, au Japon, en Corée du Sud, à Singapour et au Vietnam. ABN ASIA est l'endroit où l'académie et la technologie rencontrent l'opportunité. Avec nos solutions de pointe et nos services de développement logiciel compétents, nous aidons les entreprises à se développer et à s'imposer sur la scène mondiale. Notre engagement : Plus vite. Mieux. Plus fiable. Dans la plupart des cas : moins cher également.
N'hésitez pas à nous contacter chaque fois que vous avez besoin de services informatiques, de conseils en matière de numérique, de solutions logicielles prêtes à l'emploi, ou si vous souhaitez nous envoyer des demandes de propositions (RFP). Vous pouvez nous contacter à l'adresse [email protected]. Nous sommes prêts à vous aider avec tous vos besoins technologiques.

© ABN ASIA