- Diterbitkan pada
Float32, Float16 atau BFloat16!
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
Mengapa hal itu penting untuk Pembelajaran Dalam (Deep Learning)?
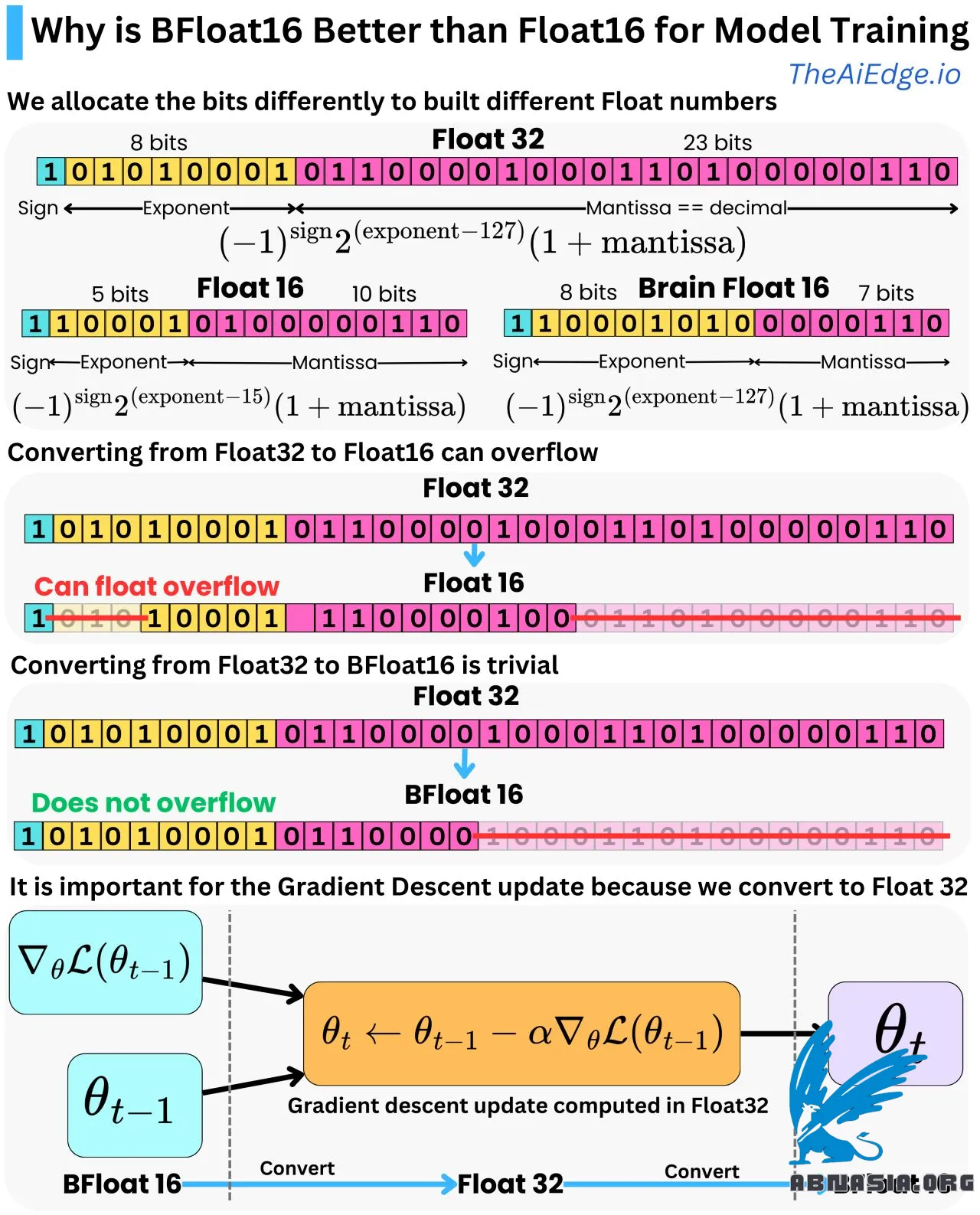
Itu hanya tingkat presisi yang berbeda. Float32 adalah cara untuk merepresentasikan bilangan titik mengambang dengan 32 bit (1 atau 0), dan Float16 / BFloat16 adalah cara untuk merepresentasikan bilangan yang sama dengan hanya 16 bit. Dengan Float32, kita mengalokasikan bit pertama untuk merepresentasikan tanda, 8 bit berikutnya untuk merepresentasikan eksponen, dan 23 bit berikutnya untuk merepresentasikan titik desimal (juga disebut Mantissa). Kita dapat mengubah representasi bit ke representasi desimal dengan menggunakan rumus sederhana:
Float32 = (-1)^tanda * 2^(eksponen - 127) * (1 + mantissa)
Dan ini dapat berkisar antara -3,4e^38 dan 3,4e^38.
Float16 menggunakan 1 bit untuk tanda, 5 bit untuk eksponen, dan 10 bit untuk Mantissa dengan rumus:
Float16 = (-1)^tanda * 2^(eksponen - 15) * (1 + mantissa)
Dan kisarannya antara -6,55e^4 dan 6,55e^4 (jauh lebih kecil!). Untuk mengubah dari Float32 ke Float16, Anda hanya perlu menghapus digit yang tidak dapat dimasukkan dalam 5 dan 10 bit yang dialokasikan untuk eksponen dan Mantissa. Untuk Mantissa, Anda hanya membuat kesalahan pembulatan, tetapi jika bilangan Float32 lebih besar dari 6,55e^4, Anda akan membuat kesalahan overflow float! Jadi, sangat mungkin untuk mendapatkan kesalahan konversi dari Float32 ke Float16.
Brain Float 16 (BFloat16) adalah representasi float lain dalam 16 bit. Kami memberikan presisi desimal yang lebih rendah tetapi memiliki kisaran yang sama dengan Float32. Kami memiliki 8 bit untuk eksponen dan 7 bit untuk Mantissa dengan rumus konversi yang sama:
BFloat16 = (-1)^tanda * 2^(eksponen - 127) * (1 + mantissa)
Memberikan kisaran yang sama dengan Float32 [-3,4e^38 dan 3,4e^38]. Jadi, mengubah ke BFloat16 dari Float32 sangatlah sederhana karena Anda hanya perlu membulatkan Mantissa.
Ini sangat penting untuk Pembelajaran Dalam karena, dalam algoritma backpropagation, parameter model diperbarui oleh pengoptimasi gradien turun (misalnya, Adam), dan perhitungan dilakukan dengan presisi Float32 untuk memastikan kesalahan pembulatan yang lebih sedikit. Parameter model dan gradien biasanya disimpan dalam memori dalam Float16 untuk mengurangi tekanan pada memori, sehingga kita perlu mengubah antara Float16 dan Float32. BFloat16 adalah pilihan yang baik karena mencegah kesalahan overflow float sambil menjaga presisi yang cukup untuk fase maju dan mundur dari algoritma backpropagation.
Harap dicatat bahwa versi bahasa Indonesia didukung oleh AI dan karena itu mungkin terjadi kesalahan kecil.
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA