- Diterbitkan pada
Mengapa GraphRAG salah satu sistem RAG terbaik
- Penulis

- Nama
- AbnAsia.org
- @steven_n_t
Basis Data Grafik seharusnya menjadi pilihan yang lebih baik untuk Generasi yang Ditingkatkan dengan Pencarian (RAG)!
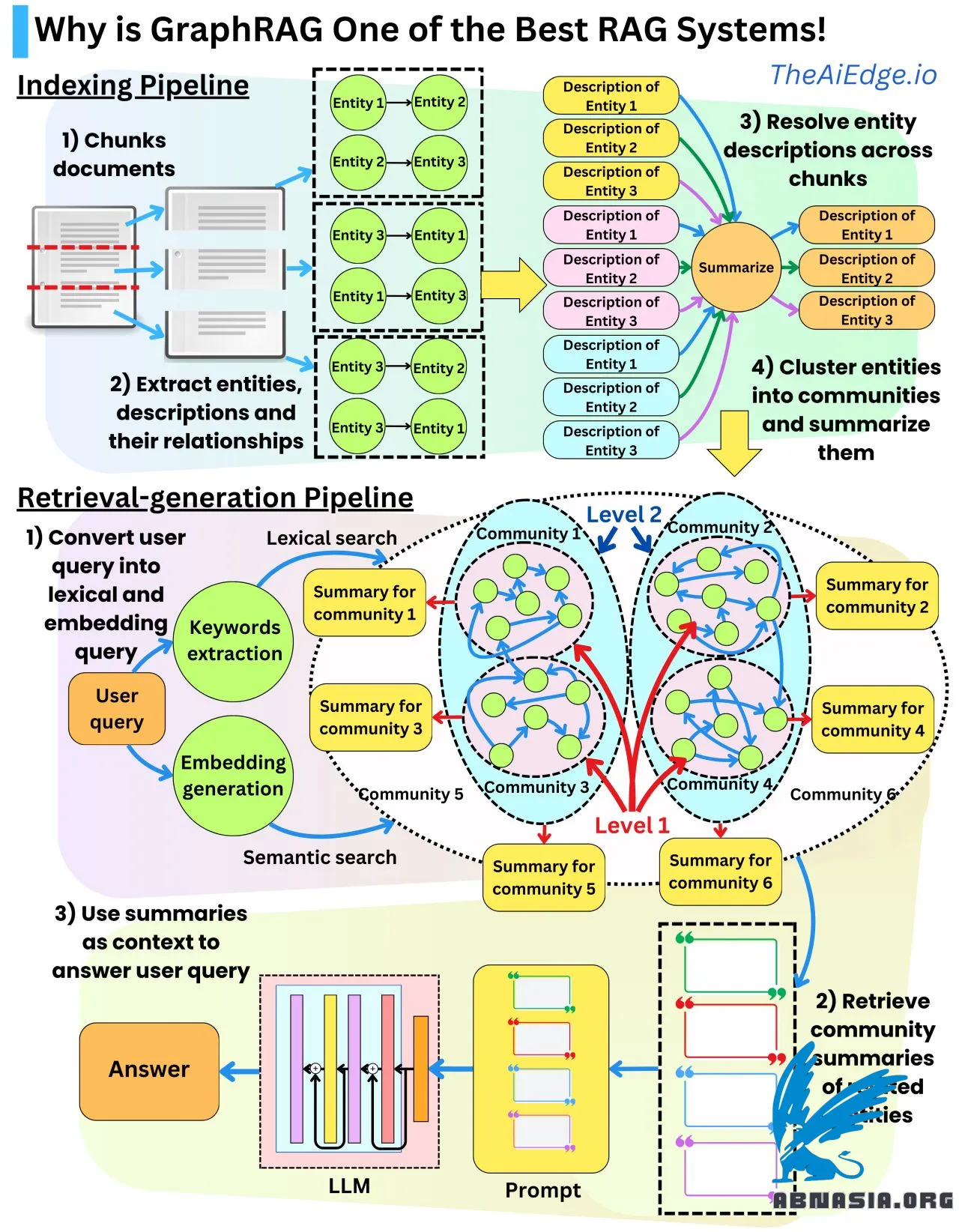
Sistem RAG biasanya cukup buruk dalam mengambil konteks yang tepat! Informasi yang diperoleh sangat lokal untuk dokumen asli, dan mungkin sulit untuk mendapatkan dokumen yang sebenarnya terkait dengan pertanyaan pengguna. Itulah tempat Microsoft GraphRAG dapat memberikan solusi!
Terdapat 2 bagian penting. Pertama, kita akan membuat ringkasan dari dokumen yang berbeda pada skala yang berbeda. Dengan cara ini, kita dapat memahami secara keseluruhan apa informasi global yang terkandung dalam dokumen lengkap, serta informasi lokal yang terkandung dalam potongan teks yang lebih kecil. Kedua, kita akan mengurangi informasi tekstual menjadi bentuk grafis. Asumsinya adalah informasi yang terkandung dalam teks dapat diwakili sebagai sekumpulan node dan edge. Ini memungkinkan representasi informasi lengkap yang terkandung dalam teks sebagai basis pengetahuan yang dapat disimpan dalam basis data grafik.
Pipa indeksasi data adalah sebagai berikut:
- Kita membagi dokumen asli menjadi sub-teks.
- Kita mengekstrak entitas, hubungan, dan deskripsi mereka dalam format terstruktur dengan menggunakan LLM.
- Kita menyelesaikan entitas dan hubungan duplikat yang dapat kita temukan di berbagai potongan teks. Kita dapat merangkum deskripsi yang berbeda menjadi lebih lengkap.
- Kita membangun representasi grafis dari entitas dan hubungan mereka
- Dari grafik, kita mengelompokkan entitas yang berbeda menjadi komunitas dalam cara hierarkis dengan menggunakan algoritma Leiden. Setiap entitas termasuk dalam beberapa klaster tergantung pada skala klaster.
- Untuk setiap komunitas, kita merangkumnya dengan menggunakan deskripsi entitas dan hubungan. Kita memiliki beberapa ringkasan untuk setiap entitas yang mewakili skala yang berbeda dari komunitas.
Pada saat pengambilan, kita dapat mengonversi pertanyaan pengguna dengan mengekstrak kata kunci untuk pencarian leksikal dan representasi vektor untuk pencarian semantik. Dari pencarian, kita mendapatkan entitas, dan dari entitas, kita mendapatkan ringkasan komunitas yang terkait. Ringkasan tersebut digunakan sebagai konteks dalam prompt pada saat generasi untuk menjawab pertanyaan pengguna.
Kita hanya memahami hal-hal ketika kita menerapkannya.
Harap dicatat bahwa versi bahasa Indonesia didukung oleh AI dan karena itu mungkin terjadi kesalahan kecil.
Penulis
Ai Base Network (ABN), ABN ASIA didirikan oleh orang-orang dengan akar yang kuat di dunia akademis, dengan pengalaman kerja di Amerika Serikat, Belanda, Hungaria, Jepang, Korea Selatan, Singapura, dan Vietnam. ABN Asia adalah tempat di mana akademik dan teknologi bertemu dengan peluang. Dengan solusi terdepan kami dan layanan pengembangan perangkat lunak yang kompeten, kami membantu bisnis untuk meningkatkan level dan bersaing di panggung global. Komitmen kami: Lebih Cepat. Lebih Baik. Lebih handal. Dalam kebanyakan kasus: Lebih murah juga.
Jangan ragu untuk menghubungi kami jika Anda membutuhkan layanan IT, konsultasi digital, solusi perangkat lunak siap pakai, atau jika Anda ingin mengirimkan permintaan proposal (RFP). Anda dapat menghubungi kami di [email protected]. Kami siap membantu Anda dengan semua kebutuhan teknologi Anda.

© ABN ASIA