- 公開日
LLMはどのようにテキストを生成するのか?
- 著者

- 名前
- AbnAsia.org
- @steven_n_t
それは到底軽い仕事ではない。
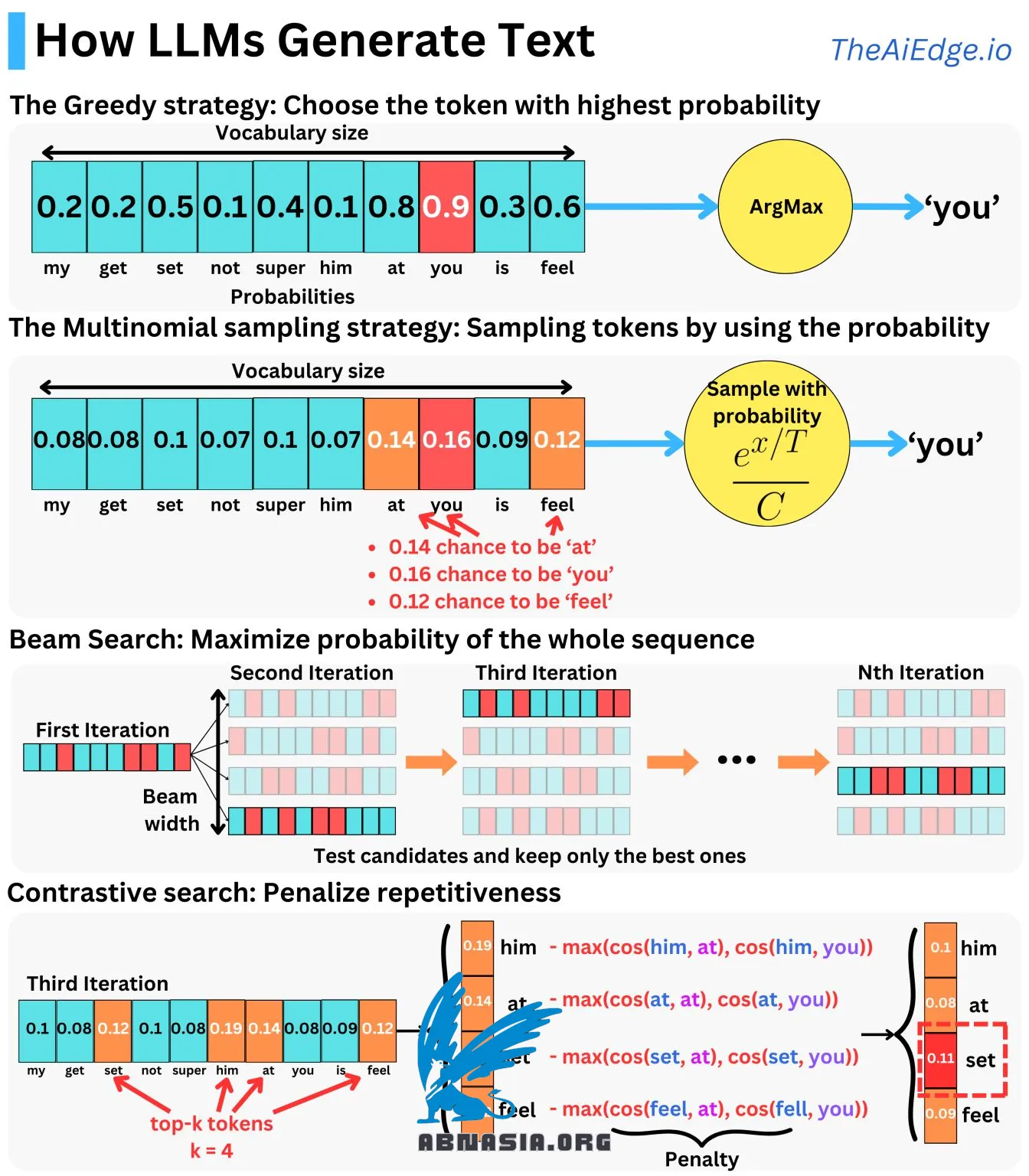
テキストを生成することは、決して単純なタスクではありません!大規模言語モデル(LLM)は、次のトークンの確率を予測するように最適化されていますが、その確率を使用してテキストを生成するにはどうすればよいのでしょうか?
ナイーブなアプローチは、モデルによって生成される確率ベクトルを使用して、最も高い確率を持つ単語を選択し、自己回帰的に処理することです。これは貪欲的なアプローチですが、生成される文章が繰り返しになり、長すぎると退化する傾向があります。別のアプローチは、モデルによって生成される確率を使用して、確率に基づいて単語をサンプリングすることです。通常、ランダム性のレベルを調整するために温度パラメータを使用します。これにより、繰り返しになることが少なく、より創造的な文章を生成できます。
しかし、これら 2 つのテクニックには問題があります。文章を生成するとき、我々は単に次のトークンの確率を最大化するのではなく、出力シーケンス全体の確率を最大化したいと考えます。
P(出力シーケンス | プロンプト)
幸いなことに、この確率を次のトークンの予測確率の積として表現できます。
P(トークン 1、...、トークン N | プロンプト)= P(トークン 1 | プロンプト)×...×P(トークン N | プロンプト、トークン 1、...、トークン N - 1)
しかし、この問題を正確に解くことは、NP-ハードな問題です。したがって、その代わりに、各イテレーションで k 個の候補トークンを選択し、テストし、シーケンス全体の確率を最大化する k 個のシーケンスを保持することで、問題を近似することができます。最後に、確率が最も高いシーケンスを選択します。これは、ビーム検索生成と呼ばれ、貪欲的なアプローチや多項分布アプローチと組み合わせることができます。
別のアプローチは、対比検索です。ここでは、流暢性や多様性などの追加メトリックを考慮します。各イテレーションで、候補トークンを選択し、事前に生成されたトークンの類似度メトリックを使用して確率を罰則し、新しいスコアを最大化するトークンを選択します。
日本語版は Ai 支援を使用しているため、小さな間違いが存在する可能性があることをご了承ください。
著者
Ai Base Network (ABN), ABN ASIAは、アカデミアに深く関わり、アメリカ、オランダ、ハンガリー、日本、韓国、シンガポール、ベトナムでの仕事経験を持つ人々によって設立されました。ABN ASIAは、学問とテクノロジーが機会と出会う場所です。最先端のソリューションと優れたソフトウェア開発サービスにより、ビジネスがレベルアップし、グローバルシーンに挑戦できるよう支援しています。 私ちの取り組み: より速く。 より良い。 より信頼性が高くなります。 ほとんどの場合、価格も安くなります。
いつでも、ITサービス、デジタルコンサルティング、既製のソフトウェアソリューション、または提案依頼書(RFP)をお探しの際は、お気軽にお問い合わせください。お問い合わせ先は[email protected]です。お客様のテクノロジーに関するニーズにお応えします。

© ABN ASIA