- เผยแพร่เมื่อ
10 ข้อพื้นฐานสำคัญของวิทยาศาสตร์ข้อมูล
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
เข้าใจแนวคิดเหล่านี้ เพื่อที่คุณจะได้มีคำศัพท์กลางร่วมกับนักวิทยาศาสตร์ข้อมูล
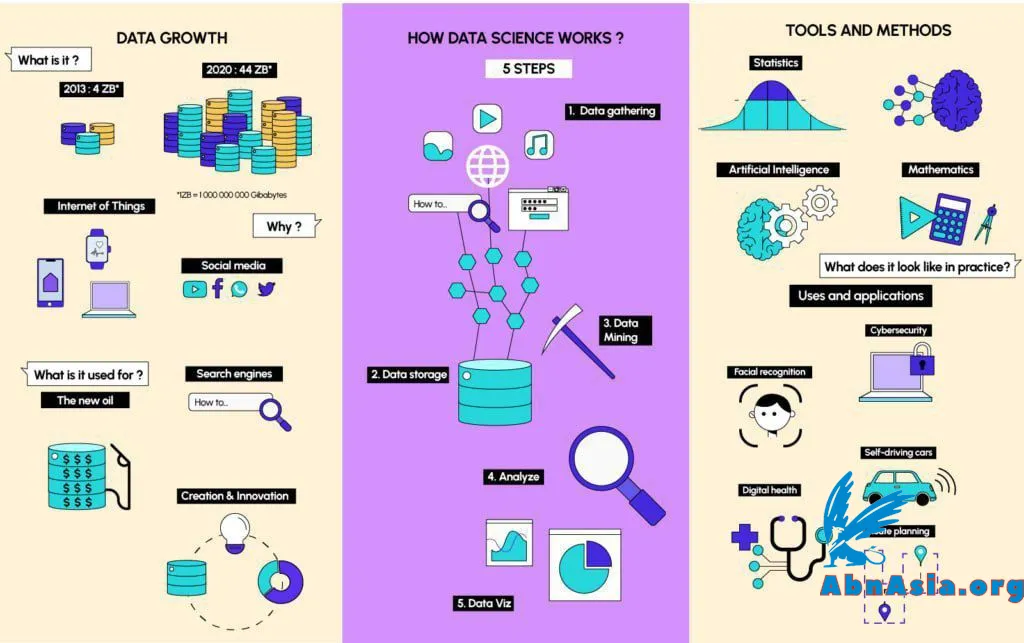
การทำความสะอาดข้อมูล (Data Cleaning) : การทำความสะอาดข้อมูลเป็นกระบวนการในการระบุและแก้ไขหรือลบข้อผิดพลาด ความไม่สอดคล้อง และความไม่ถูกต้องในเซตข้อมูล มันเป็นขั้นตอนที่สำคัญในกระบวนการทางวิทยาศาสตร์ข้อมูล เนื่องจากมันช่วยให้มั่นใจในคุณภาพและความน่าเชื่อถือของข้อมูล
การวิเคราะห์ข้อมูลแบบสำรวจ (Exploratory Data Analysis - EDA) : EDA เป็นกระบวนการในการวิเคราะห์และแสดงภาพข้อมูลเพื่อให้เข้าใจรูปแบบและความสัมพันธ์ที่ซ่อนอยู่ มันเกี่ยวข้องกับเทคนิคต่างๆ เช่น สถิติสรุป การแสดงภาพข้อมูล และการวิเคราะห์ความสัมพันธ์
การออกแบบคุณลักษณะ (Feature Engineering) : การออกแบบคุณลักษณะเป็นกระบวนการในการสร้างคุณลักษณะใหม่หรือแปลงคุณลักษณะที่มีอยู่ในเซตข้อมูลเพื่อปรับปรุงประสิทธิภาพของโมเดลการเรียนรู้ของเครื่อง มันเกี่ยวข้องกับเทคนิคต่างๆ เช่น การเข้ารหัสตัวแปรประเภท การปรับขนาดตัวแปรตัวเลข และการสร้างเงื่อนไขโต้ตอบ
ระบบการเรียนรู้ของเครื่อง (Machine Learning Algorithms) : ระบบการเรียนรู้ของเครื่องเป็นแบบจำลองทางคณิตศาสตร์ที่เรียนรู้รูปแบบและความสัมพันธ์จากข้อมูลเพื่อทำนายหรือตัดสินใจ ระบบการเรียนรู้ของเครื่องสำคัญๆ ได้แก่ การถดถอยเชิงเส้น การถดถอยเชิงลอจิสติก ต้นไม้ตัดสินใจ ป่าแบบสุ่ม เครื่องจักรเวกเตอร์สนับสนุน และเครือข่ายประสาท
การประเมินและตรวจสอบโมเดล (Model Evaluation and Validation) : การประเมินและตรวจสอบโมเดลเกี่ยวข้องกับการประเมินประสิทธิภาพของโมเดลการเรียนรู้ของเครื่องในข้อมูลที่ไม่เคยเห็นมาก่อน มันเกี่ยวข้องกับเทคนิคต่างๆ เช่น การแบ่งข้อมูลแบบไขว้ เมทริกซ์ความสับสน ความแม่น ความถูกต้อง คะแนน F1 และการวิเคราะห์เส้นโค้ง ROC
การเลือกคุณลักษณะ (Feature Selection) : การเลือกคุณลักษณะเป็นกระบวนการในการเลือกคุณลักษณะที่เกี่ยวข้องมากที่สุดจากเซตข้อมูลเพื่อปรับปรุงประสิทธิภาพของโมเดลและลดการปรับให้เหมาะสมมากเกินไป มันเกี่ยวข้องกับเทคนิคต่างๆ เช่น การวิเคราะห์ความสัมพันธ์ การกำจัดแบบย้อนกลับ การเลือกแบบไปข้างหน้า และวิธีการปรับให้เหมาะสม
การลดมิติ (Dimensionality Reduction) : เทคนิคการลดมิติใช้ในการลดจำนวนคุณลักษณะในเซตข้อมูลในขณะที่เก็บข้อมูลที่สำคัญไว้ การวิเคราะห์องค์ประกอบหลัก (PCA) และ t-SNE (t-Distributed Stochastic Neighbor Embedding) เป็นเทคนิคการลดมิติทั่วไป
การปรับโมเดลให้เหมาะสม (Model Optimization) : การปรับโมเดลให้เหมาะสมเกี่ยวข้องกับการปรับพารามิเตอร์และไฮเปอร์พารามิเตอร์ของโมเดลการเรียนรู้ของเครื่องเพื่อให้ได้ประสิทธิภาพที่ดีที่สุด เทคนิคต่างๆ เช่น การค้นหาแบบกริด การค้นหาแบบสุ่ม และการปรับให้เหมาะสมแบบเบย์ใช้ในการปรับโมเดลให้เหมาะสม
การแสดงภาพข้อมูล (Data Visualization) : การแสดงภาพข้อมูลเป็นการแสดงภาพข้อมูลในรูปแบบกราฟิกเพื่อสื่อสารข้อมูลและรูปแบบอย่างมีประสิทธิภาพ มันเกี่ยวข้องกับการใช้แผนภูมิ กราฟ และแผนภูมิเพื่อนำเสนอข้อมูลในรูปแบบที่สวยงามและเข้าใจได้ง่าย
การวิเคราะห์ข้อมูลขนาดใหญ่ (Big Data Analytics) : การวิเคราะห์ข้อมูลขนาดใหญ่หมายถึงกระบวนการในการวิเคราะห์ข้อมูลขนาดใหญ่และซับซ้อนที่ไม่สามารถประมวลผลได้ด้วยเทคนิคประมวลผลข้อมูลแบบดั้งเดิม มันเกี่ยวข้องกับเทคโนโลยีต่างๆ เช่น Hadoop Spark และการประมวลผลแบบกระจายเพื่อแยกข้อมูลเชิงลึกจากข้อมูลจำนวนมาก
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA