- เผยแพร่เมื่อ
4 กลยุทธ์สำหรับการฝึกอบรมหลาย GPU อธิบายด้วยภาพ
- ผู้เขียน

- ชื่อ
- AbnAsia.org
- @steven_n_t
โดยค่าเริ่มต้น โมเดลการเรียนรู้เชิงลึกจะใช้การ์ดจอ GPU เพียงตัวเดียวในการฝึกอบรม แม้ว่าจะมีการ์ดจอ GPU หลายตัวพร้อมใช้งานก็ตาม มีวิธีแก้ปัญหาดังนี้
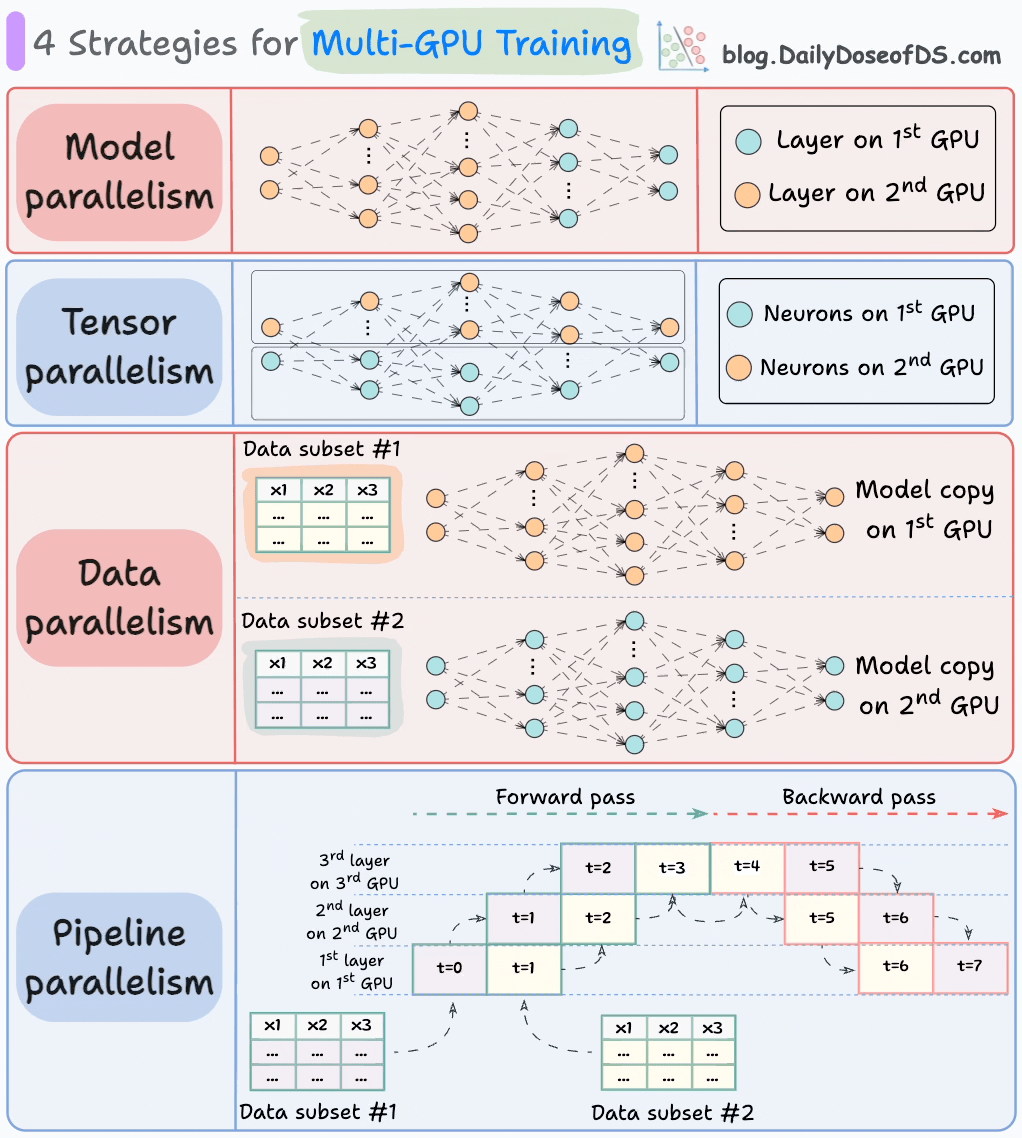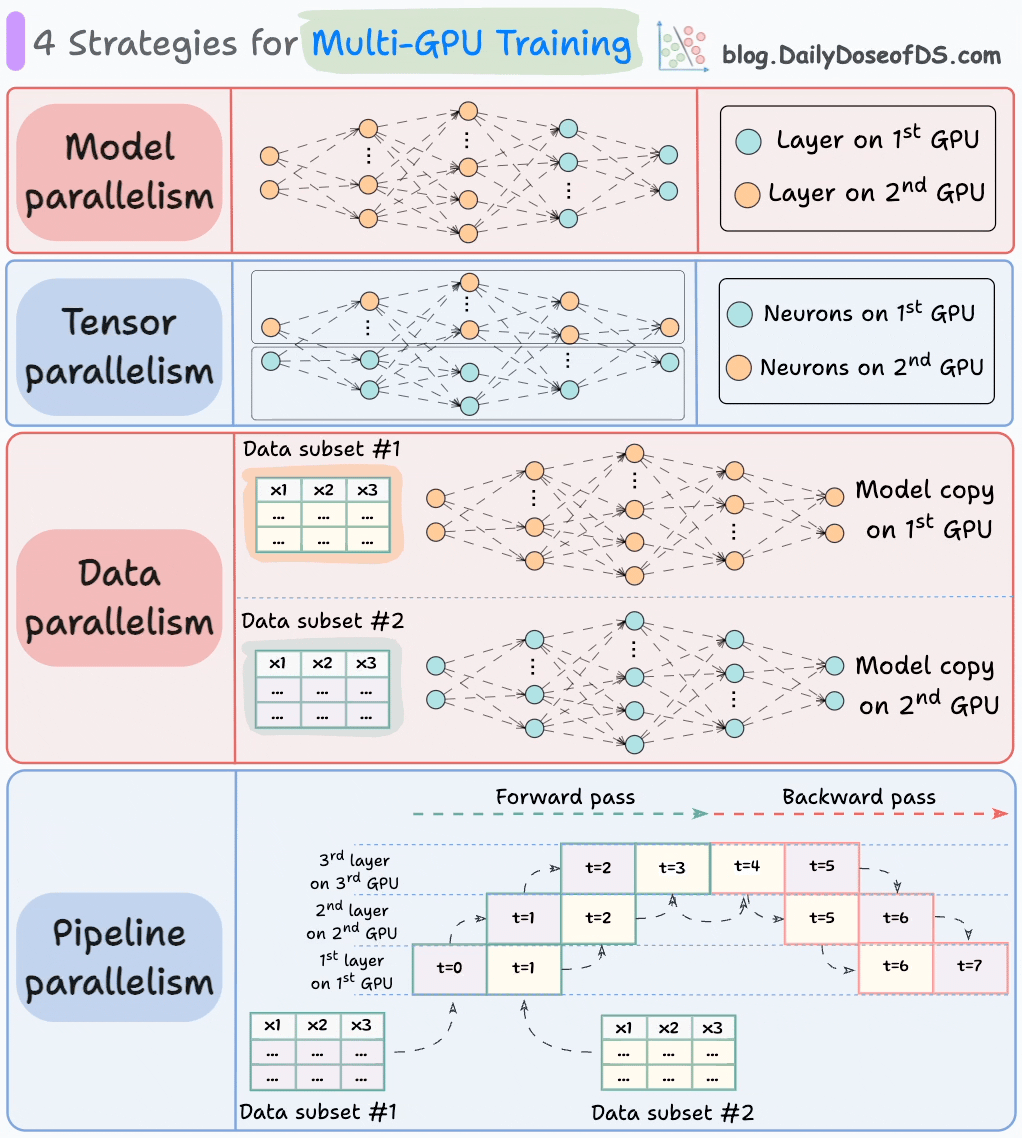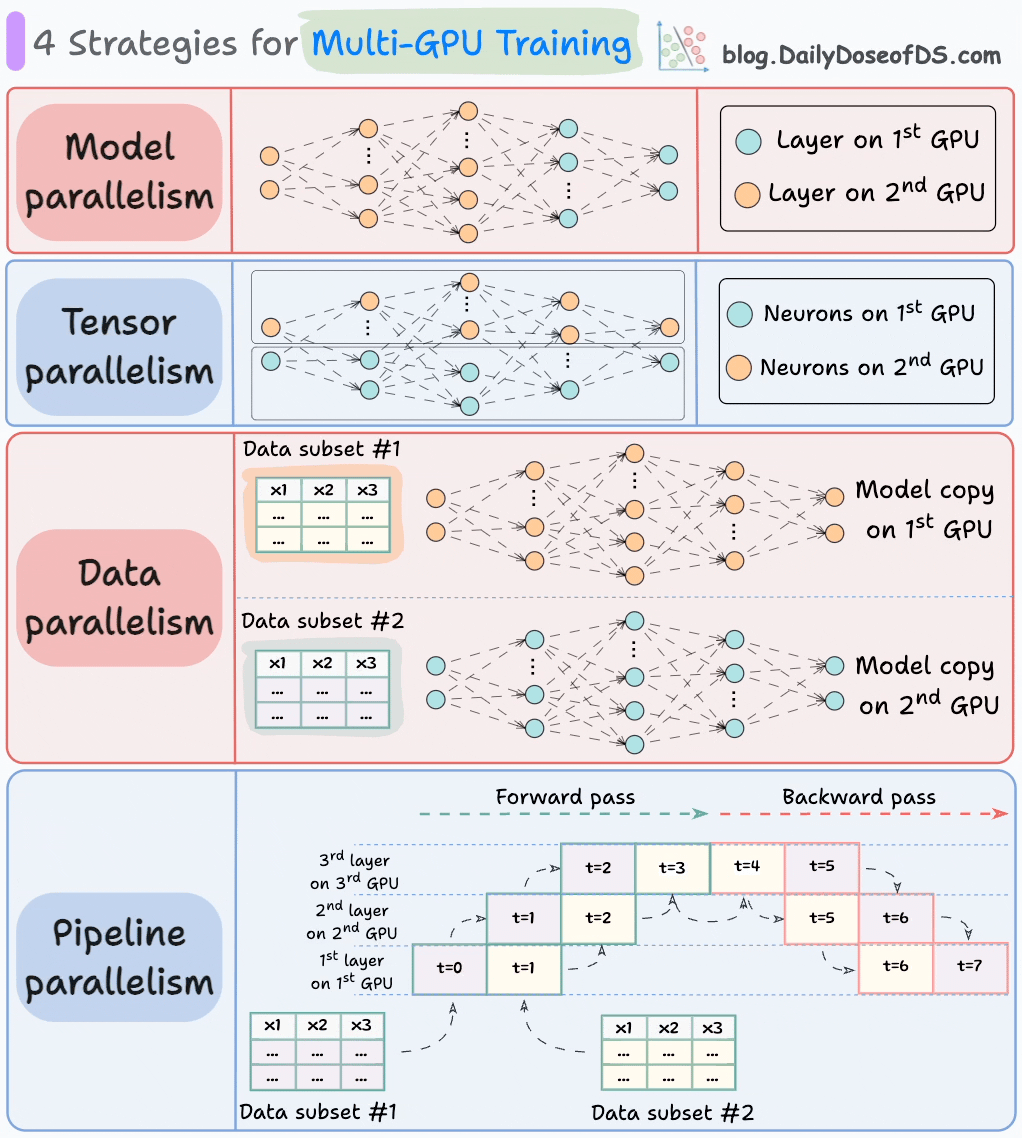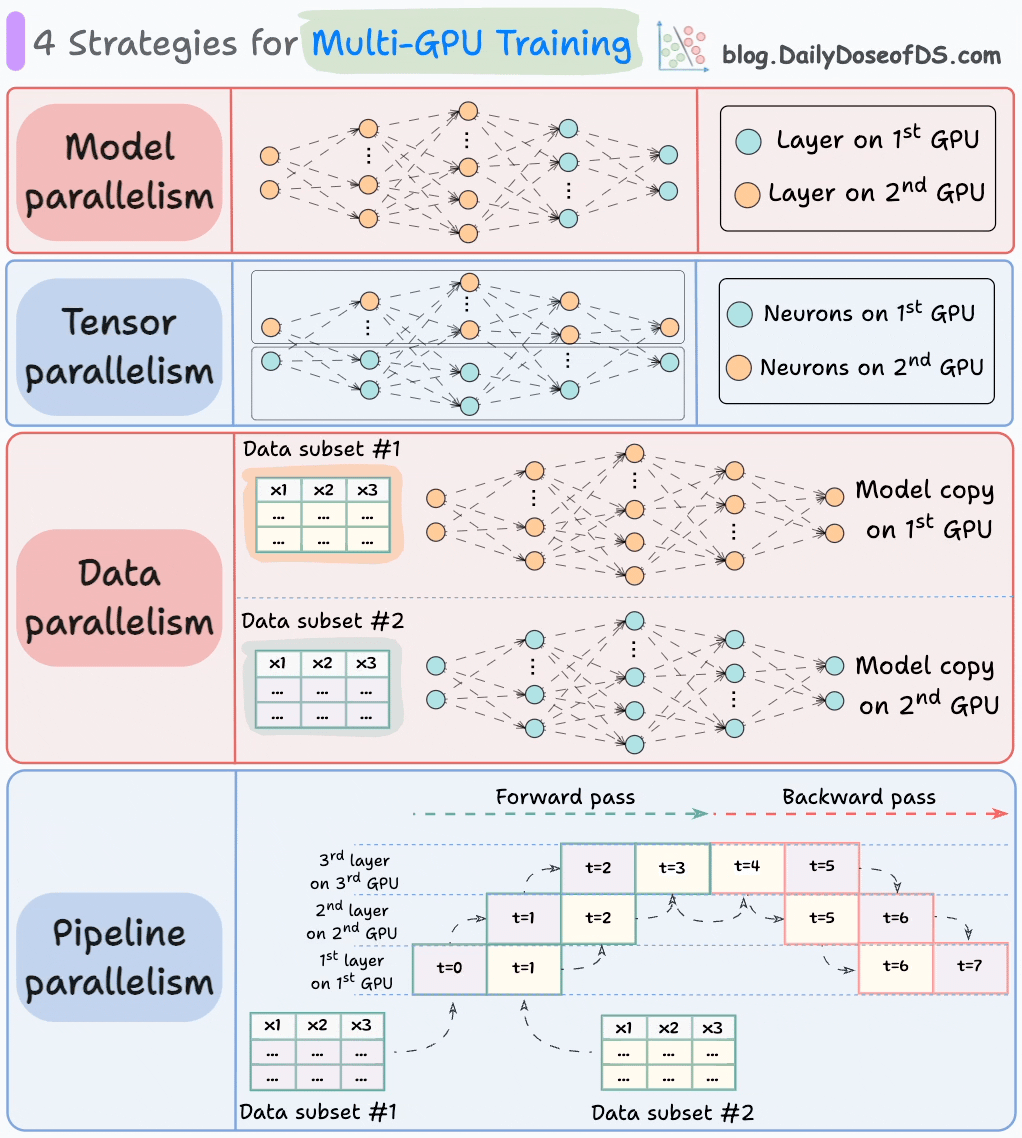
วิธีที่เหมาะสมในการดำเนินการต่อ (โดยเฉพาะในสถานการณ์ข้อมูลขนาดใหญ่) คือการกระจายภาระงานฝึกอบรมไปทั่วหลายตัวของ GPU
แผนภาพด้านล่างแสดงถึงกลยุทธ์ที่พบบ่อยสี่ประการที่ใช้ในการฝึกอบรมแบบหลาย GPU:
- ความขนานของแบบจำลอง
- ส่วนต่างๆ (หรือชั้น) ของแบบจำลองถูกวางไว้ใน GPU ที่แตกต่างกัน
- มีประโยชน์สำหรับแบบจำลองขนาดใหญ่ที่ไม่สามารถใส่ไว้ใน GPU เดียว
- อย่างไรก็ตาม ความขนานของแบบจำลองยังทำให้เกิดอุปสรรคที่รุนแรง เนื่องจากต้องมีการไหลของข้อมูลระหว่าง GPU เมื่อการกระตุ้นจาก GPU หนึ่งถูกส่งไปยังอีก GPU หนึ่ง
- ความขนานของเทนเซอร์
- แบ่งกระจายและประมวลผลการดำเนินการเทนเซอร์แต่ละรายการไปทั่วอุปกรณ์หรือโปรเซสเซอร์หลายตัว
- มันขึ้นอยู่กับแนวคิดที่ว่าการดำเนินการเทนเซอร์ขนาดใหญ่ เช่น การคูณเมทริกซ์ สามารถแบ่งออกเป็นการดำเนินการเทนเซอร์ที่เล็กกว่า และแต่ละการดำเนินการเล็กๆ สามารถดำเนินการได้ในอุปกรณ์หรือโปรเซสเซอร์ที่แยกจากกัน
- กลยุทธ์การขนานนี้มีอยู่ในตัวในมาตรฐานการนำไปใช้ของ PyTorch และเฟรมเวิร์กการเรียนรู้ลึกอื่นๆ แต่มันจะชัดเจนมากขึ้นในสถานการณ์ที่กระจาย
- ความขนานของข้อมูล
- คัดลอกแบบจำลองไปทั่วทุกตัวของ GPU
- แบ่งข้อมูลที่มีอยู่ออกเป็นชุดย่อยๆ และแต่ละชุดจะถูกประมวลผลโดย GPU ที่แยกจากกัน
- การอัปเดต (หรือความชัน) จากแต่ละ GPU จะถูกรวบรวมและใช้ในการอัปเดตพารามิเตอร์ของแบบจำลองในแต่ละ GPU
- ความขนานของพายพ์ไลน์
มักถือว่าเป็นการผสมผสานระหว่างความขนานของข้อมูลและความขนานของแบบจำลอง
ปัญหาที่เกิดขึ้นในความขนานของแบบจำลองมาตรฐานคือ GPU แรกจะไม่ทำงานเมื่อข้อมูลกำลังถูกส่งผ่านชั้นที่มีอยู่ใน GPU ที่สอง:
ความขนานของพายพ์ไลน์แก้ไขปัญหานี้โดยการโหลดชุดย่อยถัดไปของข้อมูลเมื่อ GPU แรกเสร็จสิ้นการคำนวณบนชุดย่อยแรกและถ่ายโอนการกระตุ้นไปยังชั้นที่มีอยู่ใน GPU ที่สอง
กระบวนการดูเหมือนดังนี้:
↳ ชุดย่อยแรกจะผ่านชั้นบน GPU แรก
↳ GPU ที่สองรับการกระตุ้นบนชุดย่อยแรกจาก GPU แรก
↳ ในขณะที่ GPU ที่สองส่งข้อมูลผ่านชั้น ชุดย่อยอื่นจะถูกโหลดบน GPU แรก
↳ และกระบวนการจะดำเนินต่อไป
- การใช้ GPU จะดีขึ้นอย่างมากด้วยวิธีนี้ ซึ่งเป็นที่เห็นได้จากแอนิเมชั่นด้านล่าง โดยที่หลายตัวของ GPU ถูกใช้ในเวลาเดียวกัน (ดูที่ t=1, t=2, t=5 และ t=6)
โปรดทราบว่าเวอร์ชันภาษาไทยได้รับการช่วยเหลือจาก AI ดังนั้นอาจมีข้อผิดพลาดเล็กน้อย
ผู้เขียน
Ai Base Network (ABN), ABN ASIA ถูกก่อตั้งขึ้นโดยคนที่มีรากฐานลึกในวงการวิชาการ มีประสบการณ์การทำงานในสหรัฐอเมริกา ดัตช์ ฮังการี ญี่ปุ่น เกาหลีใต้ สิงคโปร์ และเวียดนาม ABN Asia เป็นที่เราพบกันของวิทยาลัยและเทคโนโลยี ด้วยโซลูชันขั้นสูงและบริการพัฒนาซอฟต์แวร์ที่มีความสามารถ เราช่วยธุรกิจเติบโตและเข้าสู่ฉากโลก ความมุ่งมั่นของเรา: ด่วนขึ้น ดีขึ้น น่าเชื่อถือมากขึ้น ในกรณีส่วนมาก: ราคาถูกด้วย
หากคุณต้องการบริการ IT การให้คำปรึกษาดิจิทัล โซลูชันซอฟต์แวร์ใช้ได้หรือหากคุณต้องการส่งคำขอข้อเสนอ (RFPs) อย่าลังเลที่จะติดต่อเรา คุณสามารถติดต่อเราได้ที่ [email protected] เราพร้อมช่วยเหลือคุณด้านทุกความต้องการทางเทคโนโลยีของคุณทุกเมื่อ

© ABN ASIA