- Xuất bản vào
OpenAi O1: Điểm chuẩn rất tốt
- Tác giả

- Tên
- AbnAsia.org
- @steven_n_t
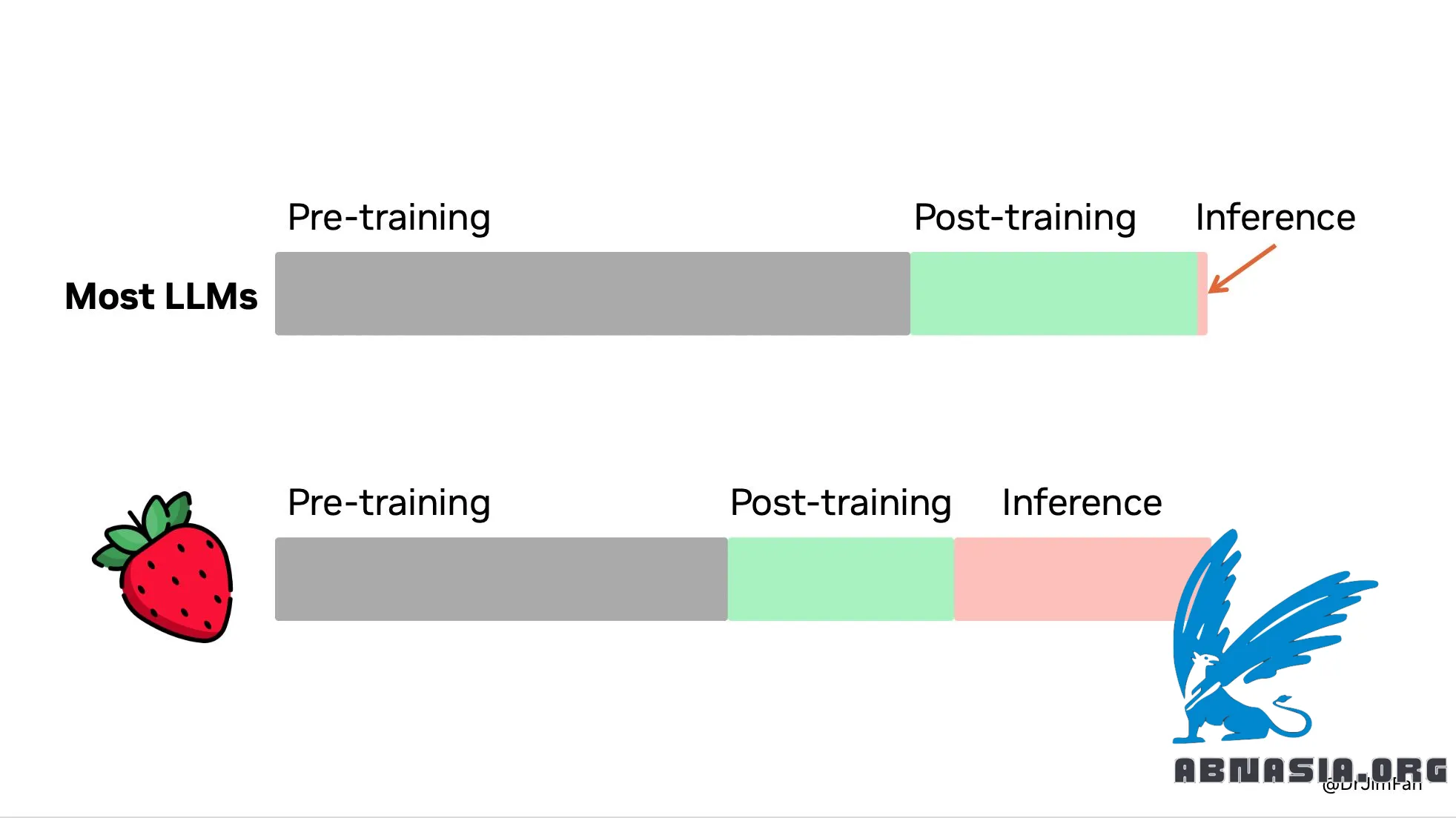
OpenAI Strawberry (o1) đã ra mắt! Cuối cùng, chúng ta đã thấy mô hình mở rộng tại thời điểm suy luận được phổ biến và triển khai trong production. Như Sutton đã nói trong bài học Bitter Lesson, chỉ có 2 kỹ thuật có thể mở rộng vô hạn với sức mạnh tính toán: học và tìm kiếm. Đã đến lúc chuyển trọng tâm sang kỹ thuật thứ hai.
Bạn không cần một mô hình khổng lồ để thực hiện suy luận. Nhiều tham số của mô hình được dành cho việc ghi nhớ dữ liệu, nhằm đạt kết quả tốt trong các bài kiểm tra như trivia QA. Có thể tách biệt suy luận ra khỏi kiến thức, tức là tạo ra một "lõi suy luận" nhỏ biết cách sử dụng các công cụ như trình duyệt và trình kiểm tra mã. Tính toán trong giai đoạn tiền huấn luyện có thể được giảm bớt.
Một lượng lớn sức mạnh tính toán sẽ được chuyển sang phục vụ giai đoạn suy luận thay vì tiền/ hậu huấn luyện. LLMs là các mô phỏng dựa trên văn bản. Bằng cách triển khai nhiều chiến lược và kịch bản có thể xảy ra trong trình mô phỏng, mô hình cuối cùng sẽ hội tụ đến những giải pháp tốt. Quá trình này là một vấn đề đã được nghiên cứu kỹ lưỡng, giống như việc tìm kiếm cây Monte Carlo (MCTS) của AlphaGo.
OpenAI có lẽ đã nắm rõ quy luật mở rộng sức mạnh tính toán trong suy luận từ lâu, trong khi giới học thuật chỉ mới phát hiện gần đây. Hai bài báo đã được công bố trên Arxiv cách nhau một tuần vào tháng trước:
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling. Brown et al. phát hiện rằng DeepSeek-Coder tăng từ 15.9% với một mẫu lên 56% với 250 mẫu trên bài kiểm tra SWE-Bench, đánh bại Sonnet-3.5.
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Snell et al. phát hiện rằng PaLM 2-S đánh bại một mô hình lớn hơn 14 lần trên bài kiểm tra MATH khi sử dụng tìm kiếm tại thời điểm kiểm tra.
Đưa o1 vào production khó hơn nhiều so với việc đạt kết quả tốt trong các bài kiểm tra học thuật. Đối với các vấn đề suy luận trong môi trường thực tế, làm thế nào để quyết định khi nào nên dừng việc tìm kiếm? Hàm thưởng là gì? Tiêu chí thành công? Khi nào cần gọi các công cụ như trình phân tích mã trong quy trình? Làm thế nào để tính đến chi phí tính toán của các quy trình CPU đó? Bài nghiên cứu của họ không chia sẻ nhiều về những điều này.
Strawberry dễ dàng trở thành một vòng quay dữ liệu tự động. Nếu câu trả lời đúng, toàn bộ dấu vết tìm kiếm trở thành một tập dữ liệu nhỏ chứa các ví dụ huấn luyện, bao gồm cả thưởng dương và thưởng âm.
Điều này giúp cải thiện lõi suy luận cho các phiên bản GPT trong tương lai, tương tự cách mà mạng giá trị của AlphaGo - được sử dụng để đánh giá chất lượng của từng vị trí trên bảng - cải thiện khi MCTS tạo ra nhiều dữ liệu huấn luyện tinh chỉnh hơn.
TÁC GIẢ
Về ABN Asia: Ai Base Network (ABN), ABN Asia được thành lập từ năm 2012, là một công ty xuất phát từ học thuật, do những giảng viên, cựu du học sinh Hungary, Hà Lan, Nga, Đức, và Nhật Bản sáng lập. Chúng tôi chia sẻ đam mê chung và tầm nhìn vững chắc về công nghệ, mang đến sự đổi mới và chất lượng đỉnh cao cho khách hàng. Phương châm của chúng tôi là: Tốt hơn. Nhanh hơn. An toàn hơn. Trong nhiều trường hợp: Rẻ hơn.
Hãy liên hệ với chúng tôi khi Quý doanh nghiệp có các nhu cầu về dịch vụ công nghệ thông tin, tư vấn chuyển đổi số, tìm kiếm các giải pháp phần mềm phù hợp, hoặc nếu Quý doanh nghiệp có đấu thầu CNTT (RFP) để chúng tôi tham dự. Quý doanh nghiệp có thể liên hệ với chúng tôi qua địa chỉ email [email protected]. Chúng tôi sẵn lòng hỗ trợ với mọi nhu cầu công nghệ của Quý doanh nghiệp.

© ABN ASIA