- 发布于
机器学习模型:模型压缩方法
- 作者

- 姓名
- AbnAsia.org
- @steven_n_t
因为他们现在太大了。
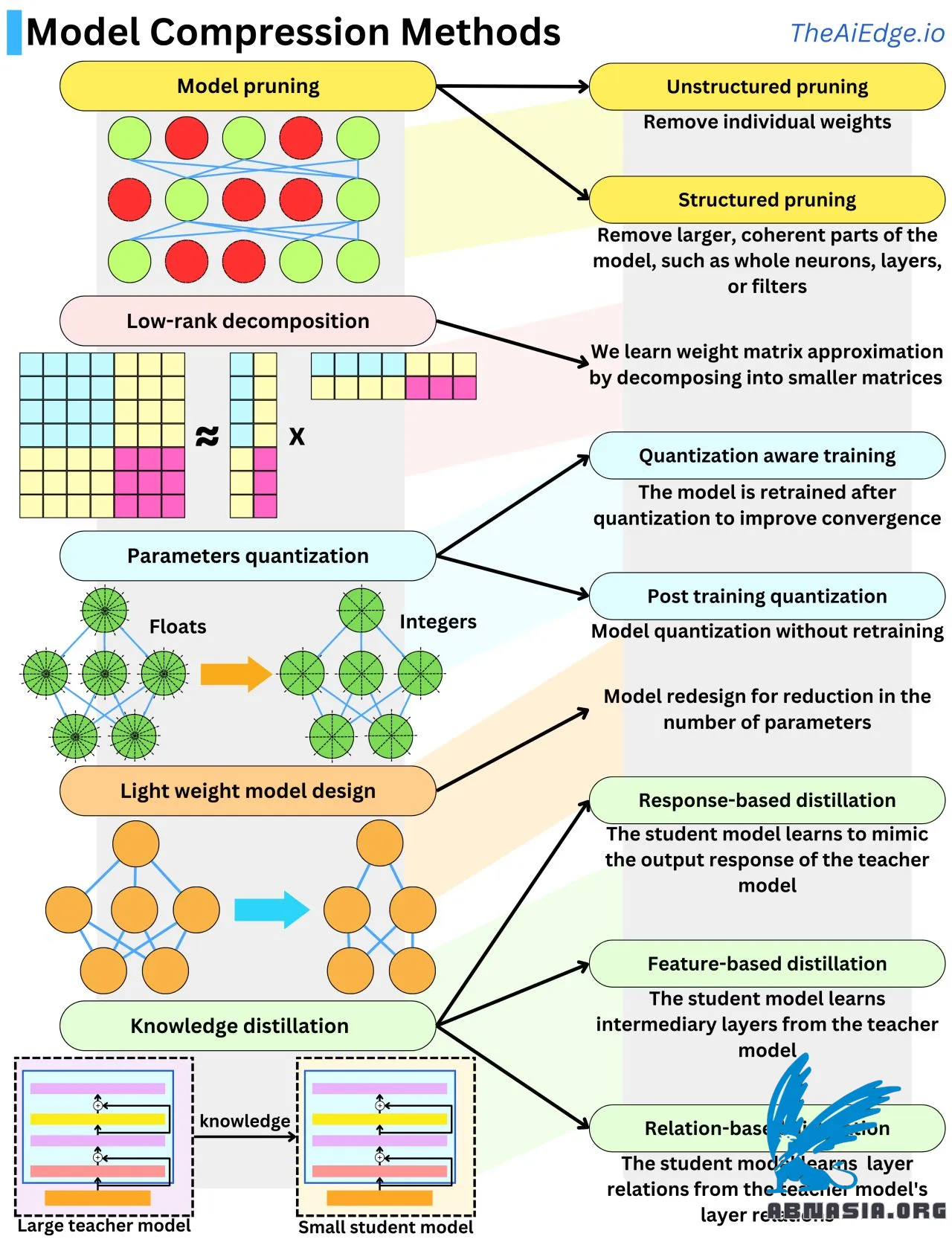
不久前,人们处理的大多数机器学习模型的内存大小仅为几GB。现在,每个新出现的生成模型的参数数量都在10亿到1万亿之间!为了理解其规模,一个浮点参数,即32位或4字节(或使用Float16时为2字节),因此这些新模型的内存大小可以在4GB到4TB之间变化,每个模型都需要在昂贵的硬件上运行。在反向传播算法期间,这些模型可能需要多达10倍的内存。由于模型规模的巨大增长,已经进行了大量研究以减小模型大小同时保持性能。压缩模型大小的主要技术有五种。
模型剪枝是关于从网络中删除不重要的权重。游戏的目标是了解在这种情况下“重要”的含义。一个常见的方法是测量每个权重对损失函数的影响。这可以通过查看损失函数的梯度和二阶导数轻松完成。另一种方法是使用L1或L2正则化并删除低幅度权重。删除整个神经元、层或滤波器称为“结构化剪枝”,在推理速度方面更高效。
模型量化是关于降低参数精度,通常是通过从浮点(32位)转换为整数(8位)。这可以实现4倍的模型压缩。量化参数会导致模型偏离其收敛点,因此通常需要使用额外的训练数据对其进行微调以保持模型性能高。我们称之为“量化感知训练”。当我们避免这一步时,它被称为“后训练量化”,并且可以对权重进行额外的启发式修改以帮助性能。
低秩分解来自神经网络权重矩阵可以用低维矩阵的乘积来近似的这一事实。一个N x N矩阵可以近似分解为两个N x 1矩阵的乘积。这是一个O(N^2) -> O(N)的空间复杂度增益!
知识蒸馏是关于从一个模型传递知识到另一个模型,通常从大模型传递到小模型。当学生模型学习生成类似的输出响应时,这被称为基于响应的蒸馏。当学生模型学习复制类似的中间层时,它被称为基于特征的蒸馏。当学生模型学习复制层之间的交互时,它被称为基于关系的蒸馏。
轻量级模型设计是关于使用来自经验结果的知识来设计更高效的架构。这可能是LLM研究中使用最多的方法之一。
请注意,中文版本是由 AI 辅助翻译的,因此可能存在细微错误。
作者
Ai Base Network (ABN), ABN ASIA由具有深厚学术背景的人员创立,他们在美国、荷兰、匈牙利、日本、韩国、新加坡和越南等国家有工作经验。ABN Asia是学术界和技术相遇的地方。凭借我们领先的解决方案和优秀的软件开发服务,我们帮助企业提升水平,走向全球舞台。我们的承诺:更快。更好。更可靠。在大多数情况下:也更便宜。
无论您需要IT服务、数字咨询、现成软件解决方案,还是想向我们发送招标要求(RFPs),都请随时与我们联系。您可以通过[email protected]与我们联系。我们随时准备为您提供所有技术需求的帮助。

© ABN ASIA